Update-regel van Double Q-learning implementeren
Double Q-learning is een uitbreiding op het Q-learning-algoritme die helpt overschatting van actie-waarden te verminderen door twee aparte Q-tabellen bij te houden en te updaten. Door de actieselectie los te koppelen van de actie-evaluatie geeft Double Q-learning een nauwkeurigere schatting van de Q-waarden. In deze oefening implementeer je de update-regel van Double Q-learning. Een lijst Q met daarin twee Q-tabellen is al aangemaakt.
De bibliotheek numpy is geïmporteerd als np, en de waarden voor gamma en alpha zijn vooraf geladen. De updateformules staan hieronder:
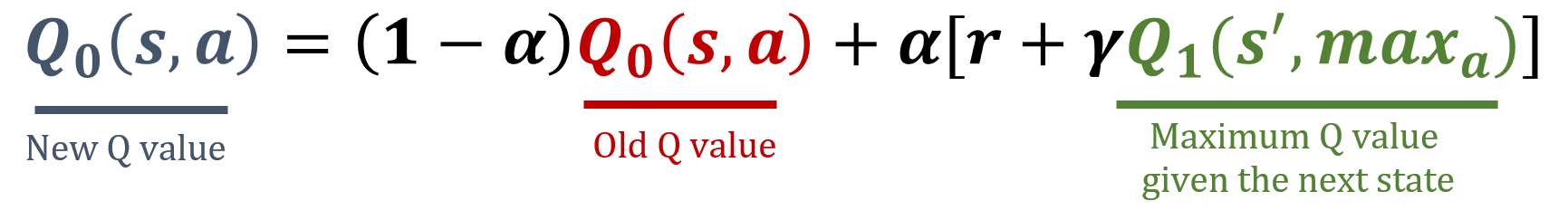
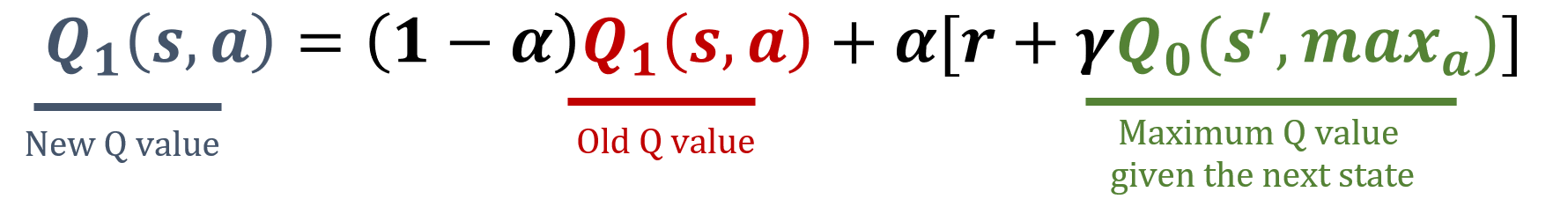
Deze oefening maakt deel uit van de cursus
Reinforcement Learning met Gymnasium in Python
Oefeninstructies
- Bepaal willekeurig welke Q-tabel in
Qje bijwerkt voor de actie-waardeschatting door de indexite berekenen. - Voer de benodigde stappen uit om
Q[i]te updaten.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____