Expected SARSA-update-regel
In deze oefening implementeer je de Expected SARSA-update-regel, een temporal-difference model-free RL-algoritme. Expected SARSA schat de verwachte waarde van het huidige beleid door te middelen over alle mogelijke acties. Dat levert een stabieler update-doel op dan SARSA. De formules die in Expected SARSA worden gebruikt, vind je hieronder.
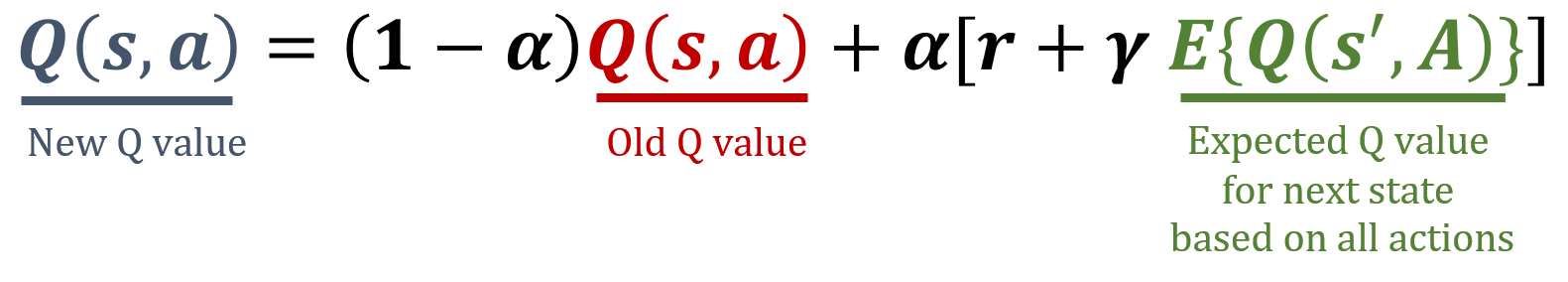
De bibliotheek numpy is geïmporteerd als np.
Deze oefening maakt deel uit van de cursus
Reinforcement Learning met Gymnasium in Python
Oefeninstructies
- Bereken de verwachte Q-waarde voor de
next_state. - Werk de Q-waarde bij voor de huidige
stateenactionmet de Expected SARSA-formule. - Werk de Q-tabel
Qbij uitgaande van een agent die actie1neemt in staat2en naar staat3gaat, en daarbij een beloning van5ontvangt.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)