Het model met woordembeddings trainen
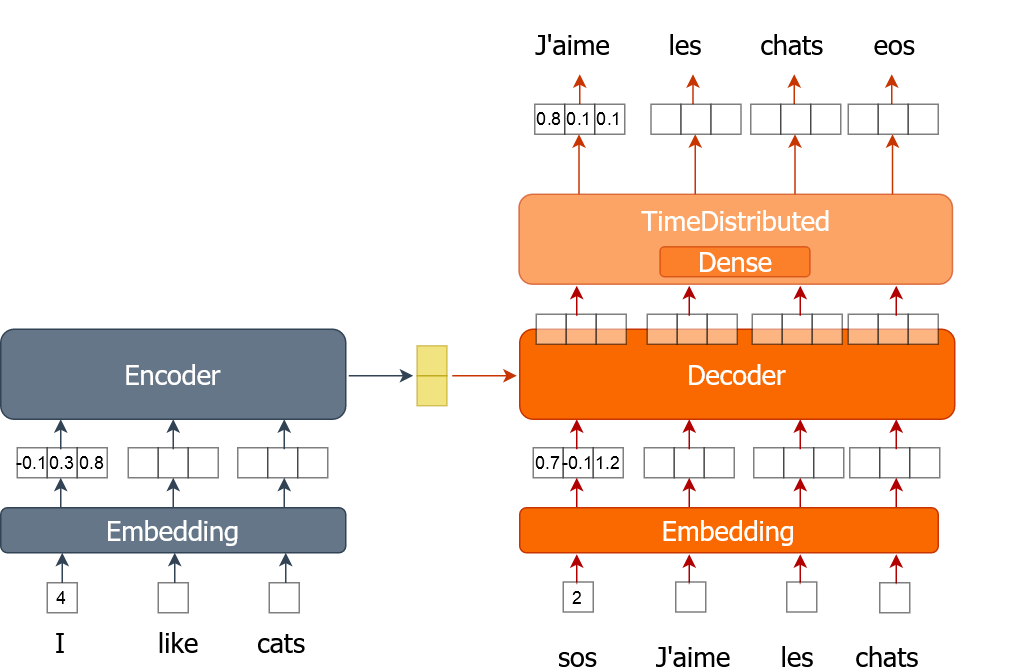
Hier leer je hoe je het trainingsproces implementeert voor een machinevertaler die woordembeddings gebruikt. Een woord wordt weergegeven als één getal in plaats van een one-hot encoded vector zoals je in eerdere oefeningen deed. Je traint het model meerdere epochs terwijl je in batches door de volledige gegevensset gaat.
Voor deze oefening krijg je trainingsdata (tr_en en tr_fr) in de vorm van een lijst met zinnen. Je gebruikt alleen een heel kleine steekproef (1000 zinnen) van de echte data, omdat trainen anders erg lang kan duren. Je hebt ook de functie sents2seqs() en het model nmt_emb die je in de vorige oefening hebt geïmplementeerd. Onthoud dat we en_x gebruiken voor encoder-inputs en de_x voor decoder-inputs.
Deze oefening maakt deel uit van de cursus
Machine Translation met Keras
Oefeninstructies
- Haal één batch Franse zinnen op zonder onehot-encoding met de functie
sents2seqs(). - Neem alle woorden behalve het laatste uit
de_xy. - Neem alle woorden behalve het eerste uit
de_xy_oh(Franse woorden met onehot-encoding). - Train het model met één batch aan data
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))