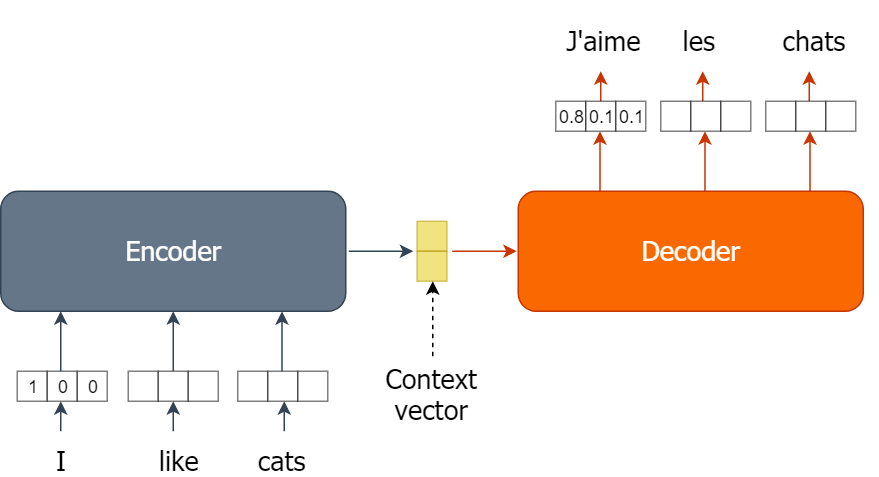
Deel 1: Tekstomkeer-model - Encoder
Een eenvoudig model bouwen dat tekst omkeert is een fijne manier om de werking van encoder-decoder-modellen en hun onderlinge koppeling te begrijpen. Je gaat nu het encoder-gedeelte van een tekstomkeer-model implementeren.
De implementatie van de encoder is opgesplitst over twee oefeningen. In deze oefening definieer je de hulpfunctie words2onehot(). De functie words2onehot() moet een lijst met woorden en een woordenboek word2index innemen en de lijst met woorden omzetten naar een array van one-hotvectoren. Het woordenboek word2index is beschikbaar in de werkruimte.
Deze oefening maakt deel uit van de cursus
Machine Translation met Keras
Oefeninstructies
- Zet woorden om naar ID's met het woordenboek
word2indexin de functiewords2onehot(). - Zet woord-ID's om naar onehot-vectoren met lengte
3(via het argumentnum_classes) en retourneer de resulterende array. - Roep de functie
words2onehot()aan met de woordenI,likeencatsen sla het resultaat op inonehot. - Print de woorden en hun bijbehorende onehot-vectoren met de functies
print()enzip(). Met de functiezip()kun je meerdere lijsten tegelijk doorlopen.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
import numpy as np
def words2onehot(word_list, word2index):
# Convert words to word IDs
word_ids = [____[w] for w in ____]
# Convert word IDs to onehot vectors and return the onehot array
onehot = ____(____, num_classes=3)
return ____
words = ["I", "like", "cats"]
# Convert words to onehot vectors using words2onehot
onehot = ____(____, ____)
# Print the result as (, ) tuples
print([(w,ohe.tolist()) for ____,____ in zip(words, ____)])