Zet wat Spark in je data
In de vorige oefening zag je hoe je data van Spark naar pandas verplaatst. Maar misschien wil je ook de andere kant op: een pandas DataFrame in een Spark-cluster zetten! De klasse SparkSession heeft hier ook een methode voor.
De methode .createDataFrame() neemt een pandas DataFrame en geeft een Spark DataFrame terug.
De output van deze methode wordt lokaal opgeslagen, niet in de catalogus van de SparkSession. Dat betekent dat je alle Spark DataFrame-methoden erop kunt gebruiken, maar dat je de data niet in andere contexten kunt benaderen.
Een SQL-query (via de methode .sql()) die naar je DataFrame verwijst, zal bijvoorbeeld een fout geven. Om de data op die manier te gebruiken, moet je die opslaan als een temporary table.
Dat kan met de Spark DataFrame-methode .createTempView(), die als enige argument de naam krijgt van de tijdelijke tabel die je wilt registreren. Deze methode registreert het DataFrame als een tabel in de catalogus, maar omdat de tabel tijdelijk is, is die alleen toegankelijk vanuit de specifieke SparkSession waarmee het Spark DataFrame is gemaakt.
Er is ook de methode .createOrReplaceTempView(). Die maakt veilig een nieuwe tijdelijke tabel aan als die nog niet bestaat, of werkt een bestaande tabel bij als die al gedefinieerd was. Je gebruikt deze methode om problemen met dubbele tabellen te voorkomen.
Bekijk het diagram om te zien hoe je Spark-datastructuren met elkaar samenwerken.
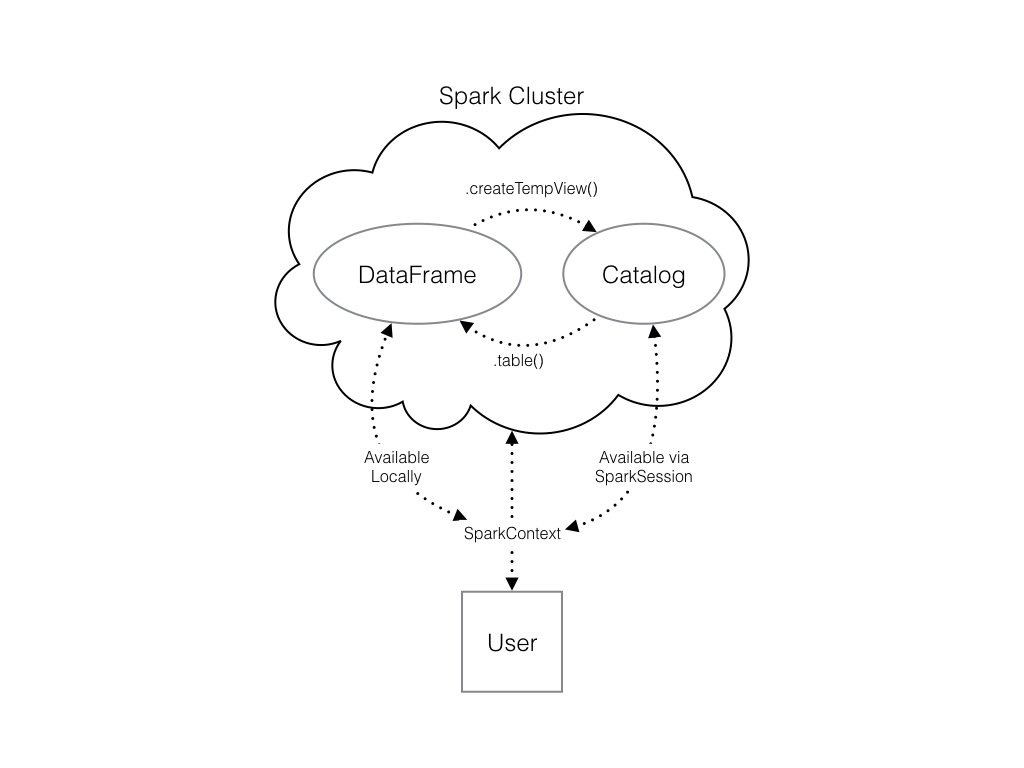
Er is al een SparkSession met de naam spark in je werkruimte, numpy is geïmporteerd als np en pandas als pd.
Deze oefening maakt deel uit van de cursus
Basis van PySpark
Oefeninstructies
- De code om een
pandasDataFrame met willekeurige getallen te maken is al gegeven en opgeslagen alspd_temp. - Maak een Spark DataFrame met de naam
spark_tempdoor de Spark-methode.createDataFrame()aan te roepen metpd_tempals argument. - Bekijk de lijst met tabellen in je Spark-cluster en controleer dat het nieuwe DataFrame er juist niet tussen staat. Je kunt hiervoor
spark.catalog.listTables()gebruiken. - Registreer het zojuist gemaakte DataFrame
spark_tempals tijdelijke tabel met de methode.createOrReplaceTempView(). De tijdelijke tabel moet"temp"heten. Vergeet niet: je stelt de tabelnaam in door die als het enige argument aan je methode mee te geven! - Bekijk de lijst met tabellen opnieuw.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Create pd_temp
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = ____
# Examine the tables in the catalog
print(____)
# Add spark_temp to the catalog
spark_temp.____
# Examine the tables in the catalog again
print(____)