Omgaan met labelruis
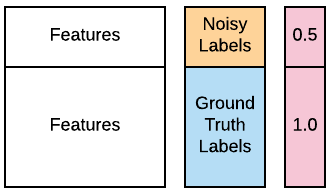
Een van je cyberanalisten laat weten dat veel labels voor de eerste 100 broncomputers in je trainingsdata mogelijk onjuist zijn door een databasefout. Ze hoopt dat je de data toch kunt gebruiken, omdat de meeste labels nog kloppen, maar vraagt je deze 100 labels als "ruis" te behandelen. Gelukkig weet jij hoe dat moet, met gewogen leren. De besmette data staat klaar in je workspace als X_train, X_test, y_train_noisy, y_test. Je wilt kijken of je de prestaties van een GaussianNB()-classifier kunt verbeteren met gewogen leren. Je kunt de optionele parameter sample_weight gebruiken, die wordt ondersteund door de .fit()-methoden van de meeste populaire classifiers. De functie accuracy_score() is al ingeladen. Je kunt de onderstaande afbeelding raadplegen voor begeleiding.
Deze oefening maakt deel uit van de cursus
Machine Learning-workflows ontwerpen in Python
Oefeninstructies
- Fit een instantie van
GaussianNB()op de trainingsdata met de besmette labels. - Rapporteer de nauwkeurigheid op de testdata met
accuracy_score(). - Maak gewichten die tweemaal zoveel gewicht toekennen aan ground-truthlabels als aan ruizige labels. Denk eraan: de gewichten hebben betrekking op de trainingsdata.
- Fit de classifier opnieuw met bovenstaande gewichten en rapporteer de nauwkeurigheid.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))