Klanten segmenteren
In deze oefening voer je een klantensegmentatie uit op de Mall Customer Segmentation Dataset met een differentieel privé-clusteringmodel.
Bij K-means-clustering kun je het optimale aantal clusters bepalen met de elbow-methode.
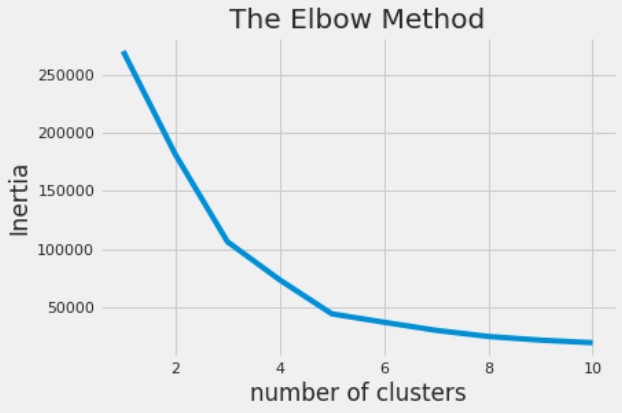
Annual Income en Spending Score, die zijn geladen als X, en je plot de resulterende clusters.
De volledige gegevensset is geladen als mall_df. Voor het gemak is een aangepaste functie show_clusters() meegeleverd om de clusters te plotten. Gebruik ?show_clusters om er meer over te leren.
Deze oefening maakt deel uit van de cursus
Dataprivacy en anonimisering in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Build the differentially private K-means model
model = ____