Performance del portafoglio con gradient boosted
A questo punto hai analizzato la previsione della probabilità di default usando sia LogisticRegression() sia XGBClassifier(). Hai visto alcuni punteggi e dei campioni di previsioni, ma qual è l’effetto complessivo sulla performance del portafoglio? Prova a usare la perdita attesa come scenario per mostrare l’importanza di testare modelli diversi.
È stato creato un data frame chiamato portfolio che combina le probabilità di default per entrambi i modelli, la loss given default (per ora ipotizza il 20%) e loan_amnt, che assumeremo essere l’esposizione al default.
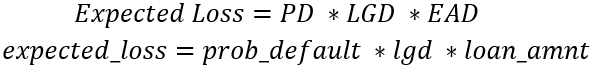
Il data frame cr_loan_prep insieme ai set di training X_train e y_train sono stati caricati nello spazio di lavoro.
Questo esercizio fa parte del corso
Credit Risk Modeling in Python
Istruzioni dell'esercizio
- Stampa le prime cinque righe di
portfolio. - Crea la colonna di
expected_lossper i modelligbtelr, chiamategbt_expected_losselr_expected_loss. - Stampa la somma di
lr_expected_lossper l’interoportfolio. - Stampa la somma di
gbt_expected_lossper l’interoportfolio.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Print the first five rows of the portfolio data frame
print(____.____())
# Create expected loss columns for each model using the formula
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
# Print the sum of the expected loss for lr
print('LR expected loss: ', np.____(____[____]))
# Print the sum of the expected loss for gbt
print('GBT expected loss: ', np.____(____[____]))