Menerapkan aturan pembaruan Double Q-learning
Double Q-learning adalah perluasan dari algoritme Q-learning yang membantu mengurangi estimasi berlebihan terhadap nilai aksi dengan memelihara dan memperbarui dua Q-table terpisah. Dengan melepaskan keterkaitan antara pemilihan aksi dan evaluasi aksi, Double Q-learning memberikan estimasi Q-value yang lebih akurat. Latihan ini memandu Anda menerapkan aturan pembaruan Double Q-learning. Sebuah daftar Q yang berisi dua Q-table telah disiapkan.
Pustaka numpy telah diimpor sebagai np, dan nilai gamma serta alpha telah dimuat sebelumnya. Rumus pembaruan ada di bawah ini:
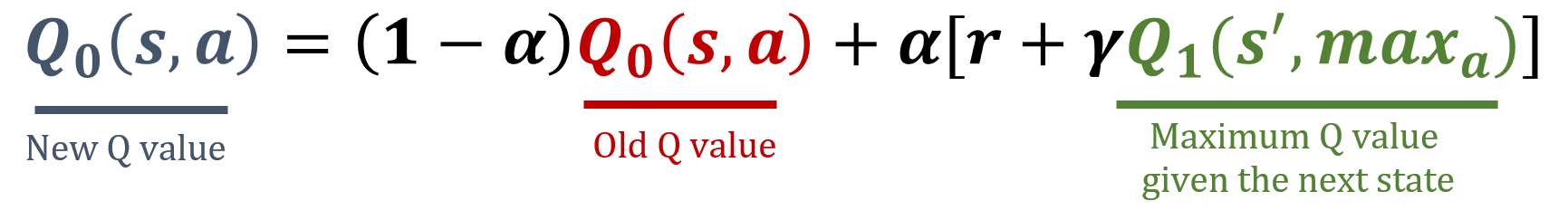
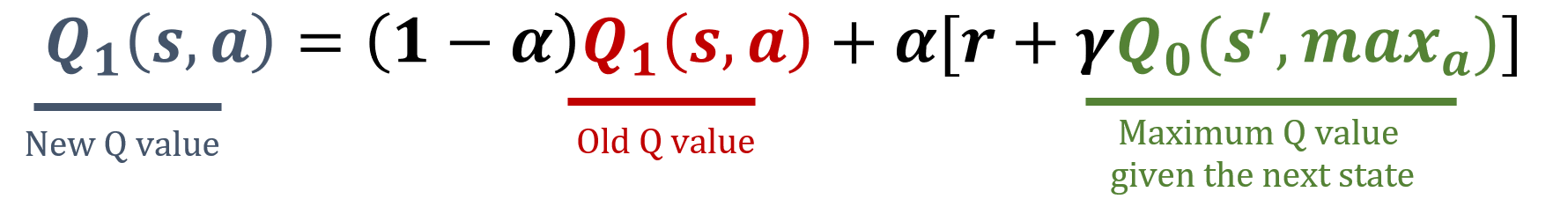
Latihan ini merupakan bagian dari kursus
Reinforcement Learning dengan Gymnasium di Python
Instruksi latihan
- Secara acak tentukan Q-table mana di dalam
Qyang akan diperbarui untuk estimasi nilai aksi dengan menghitung indeksnyai. - Lakukan langkah-langkah yang diperlukan untuk memperbarui
Q[i].
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____