Aturan pembaruan Expected SARSA
Dalam latihan ini, Anda akan mengimplementasikan aturan pembaruan Expected SARSA, sebuah algoritma temporal difference untuk RL model-free. Expected SARSA mengestimasi nilai ekspektasi dari kebijakan saat ini dengan merata-ratakan semua aksi yang mungkin, sehingga menghasilkan target pembaruan yang lebih stabil dibandingkan SARSA. Rumus yang digunakan dalam Expected SARSA ditunjukkan di bawah ini.
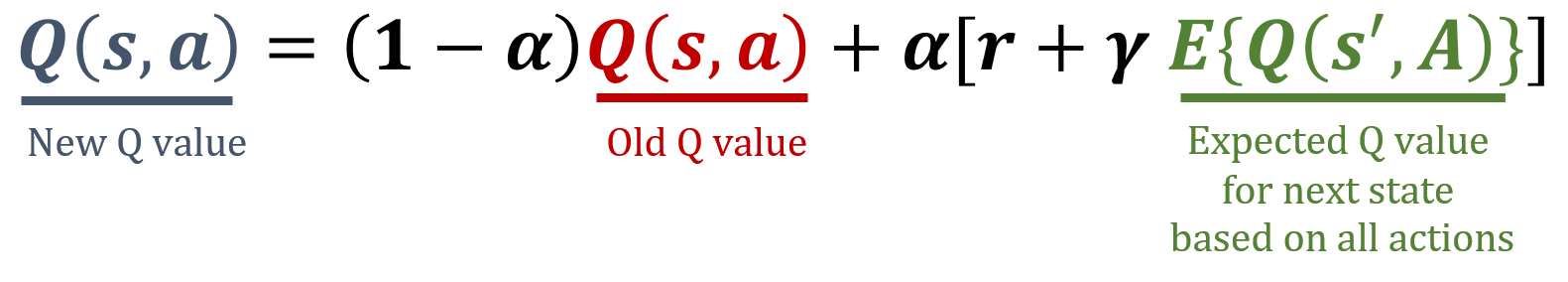
Pustaka numpy telah diimpor sebagai np.
Latihan ini merupakan bagian dari kursus
Reinforcement Learning dengan Gymnasium di Python
Instruksi latihan
- Hitung nilai Q ekspektasi untuk
next_state. - Perbarui nilai Q untuk
statedanactionsaat ini menggunakan rumus Expected SARSA. - Perbarui Q-table
Qdengan asumsi agen mengambil aksi1pada state2lalu berpindah ke state3, dan menerima reward sebesar5.
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)