Menangani label yang bising
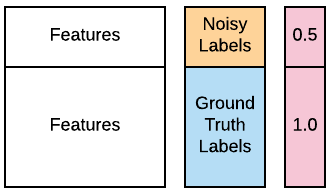
Salah satu analis siber Anda memberi tahu bahwa banyak label untuk 100 komputer sumber pertama dalam data pelatihan mungkin salah karena kesalahan basis data. Ia berharap data tersebut tetap bisa digunakan karena sebagian besar label masih benar, tetapi meminta Anda memperlakukan 100 label ini sebagai "bising". Untungnya Anda tahu cara menanganinya dengan pembelajaran berbobot. Data yang terkontaminasi tersedia di ruang kerja Anda sebagai X_train, X_test, y_train_noisy, y_test. Anda ingin melihat apakah Anda dapat meningkatkan kinerja classifier GaussianNB() dengan pembelajaran berbobot. Anda dapat menggunakan parameter opsional sample_weight, yang didukung oleh metode .fit() pada sebagian besar classifier populer. Fungsi accuracy_score() sudah dimuat. Anda dapat merujuk gambar di bawah ini untuk panduan.
Latihan ini merupakan bagian dari kursus
Merancang Alur Kerja Machine Learning di Python
Instruksi latihan
- Latih sebuah instance
GaussianNB()pada data pelatihan dengan label yang terkontaminasi. - Laporkan akurasinya pada data uji menggunakan
accuracy_score(). - Buat bobot yang memberikan bobot dua kali lebih besar pada label ground truth dibandingkan label bising. Ingat bahwa bobot diterapkan pada data pelatihan.
- Latih ulang classifier menggunakan bobot di atas dan laporkan akurasinya.
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))