Mettez du Spark dans vos données
Dans le dernier exercice, vous avez vu comment déplacer des données de Spark vers pandas. Cependant, peut-être voulez-vous aller dans l'autre sens, et mettre un DataFrame pandas dans un cluster Spark ! La classe SparkSession dispose également d'une méthode pour cela.
La méthode .createDataFrame() prend un DataFrame pandas et renvoie un DataFrame Spark.
Le résultat de cette méthode est stocké localement, et non dans le catalogue SparkSession. Cela signifie que vous pouvez utiliser toutes les méthodes DataFrame de Spark sur celui-ci, mais que vous ne pouvez pas accéder aux données dans d'autres contextes.
Par exemple, une requête SQL (utilisant la méthode .sql() ) qui fait référence à votre DataFrame provoquera une erreur. Pour accéder aux données de cette manière, vous devez les enregistrer sous la forme d'un tableau temporaire.
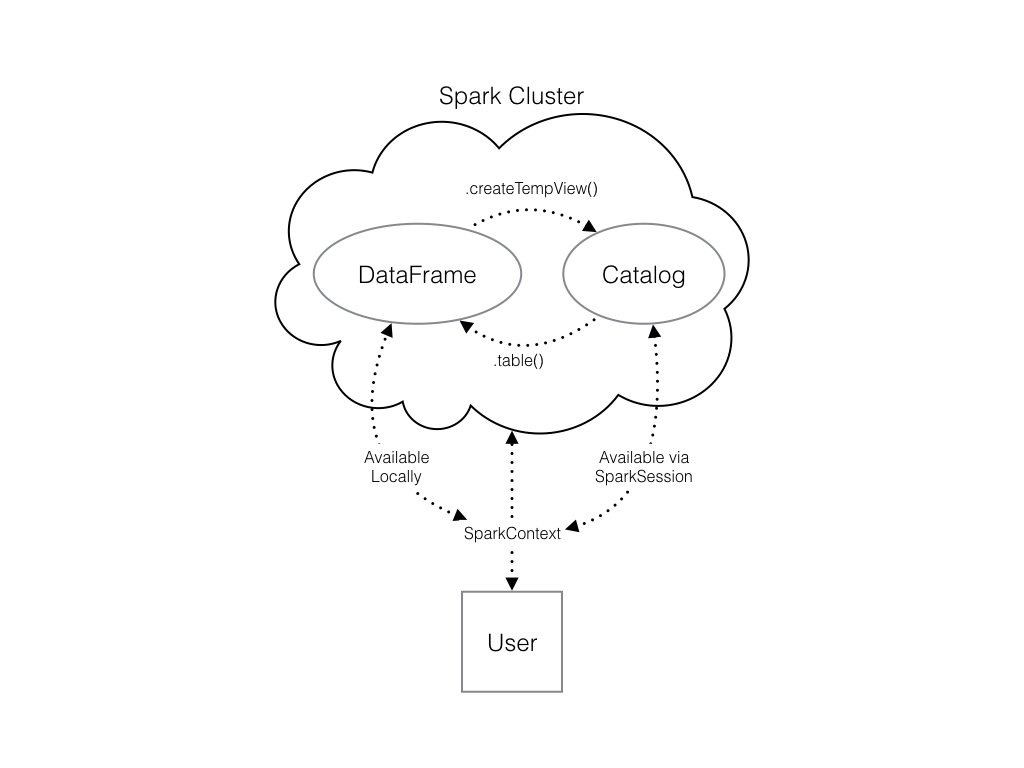
Vous pouvez le faire en utilisant la méthode .createTempView() Spark DataFrame, qui prend comme seul argument le nom du tableau temporaire que vous souhaitez enregistrer. Cette méthode enregistre le DataFrame en tant que tableau dans le catalogue, mais comme ce tableau est temporaire, il n'est accessible qu'à partir du site SparkSession spécifique utilisé pour créer le DataFrame Spark.
Il existe également la méthode .createOrReplaceTempView(). Cette opération permet de créer en toute sécurité un nouveau tableau temporaire s'il n'y en avait pas auparavant, ou de mettre à jour un tableau existant s'il en existait déjà un. Vous utiliserez cette méthode pour éviter les problèmes de tableaux en double.
Consultez le diagramme pour voir toutes les différentes façons dont vos structures de données Spark interagissent les unes avec les autres.
Il y a déjà un SparkSession appelé spark dans votre espace de travail, numpy a été importé en tant que np, et pandas en tant que pd.
Cet exercice fait partie du cours
<cours>Introduction à PySpark</cours>Instructions de l’exercice
- Le code permettant de créer un DataFrame
pandasde nombres aléatoires a déjà été fourni et enregistré souspd_temp. - Créez un DataFrame Spark appelé
spark_tempen appelant la méthode Spark.createDataFrame()avecpd_tempcomme argument. - Examinez la liste des tableaux de votre cluster Spark et vérifiez que le nouveau DataFrame n' est pas présent. N'oubliez pas que vous pouvez utiliser
spark.catalog.listTables()pour ce faire. - Enregistrez le DataFrame
spark_tempque vous venez de créer en tant que tableau temporaire à l'aide de la méthode.createOrReplaceTempView(). THe tableau temporaire doit être nommé"temp". N'oubliez pas que le nom du tableau est défini en l'incluant comme seul argument de votre méthode ! - Examinez à nouveau la liste des tableaux.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Create pd_temp
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = ____
# Examine the tables in the catalog
print(____)
# Add spark_temp to the catalog
spark_temp.____
# Examine the tables in the catalog again
print(____)