La fonction objectif de substitution tronquée
Veuillez mettre en œuvre la fonction « calculate_loss() » (Désactiver la fonction de paiement) pour PPO. Cela nécessite de coder l'innovation clé du PPO, à savoir la fonction de perte de substitution tronquée. Cela permet de limiter la mise à jour de la politique afin qu'elle ne s'éloigne pas trop de la politique précédente à chaque étape.
La formule pour l'objectif de substitution tronqué est la suivante :
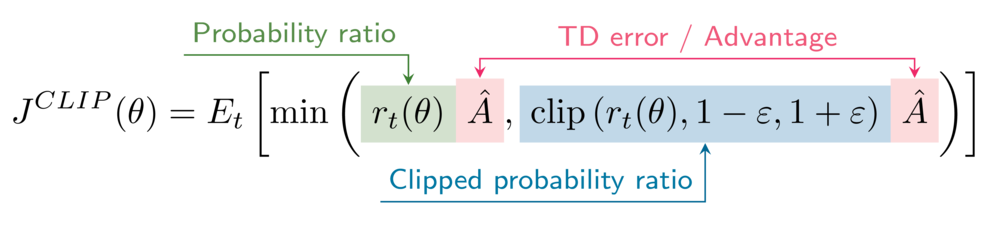
Votre environnement a l'hyperparamètre de découpage epsilon défini sur 0,2.
Cet exercice fait partie du cours
<cours>Apprentissage par renforcement profond en Python</cours>Instructions de l’exercice
- Obtenez les rapports de probabilité entre
\pi_\thetaet\pi_{\theta_{old}}(versions non tronquées et tronquées). - Calculez les objectifs de substitution (versions non tronquées et tronquées).
- Calculez l'objectif de substitution tronqué PPO.
- Veuillez calculer la perte de l'acteur.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)