L'architecture du réseau politique
Construisez l'architecture d'un réseau de politiques que vous pourrez utiliser ultérieurement pour former votre agent de gradient de politique.
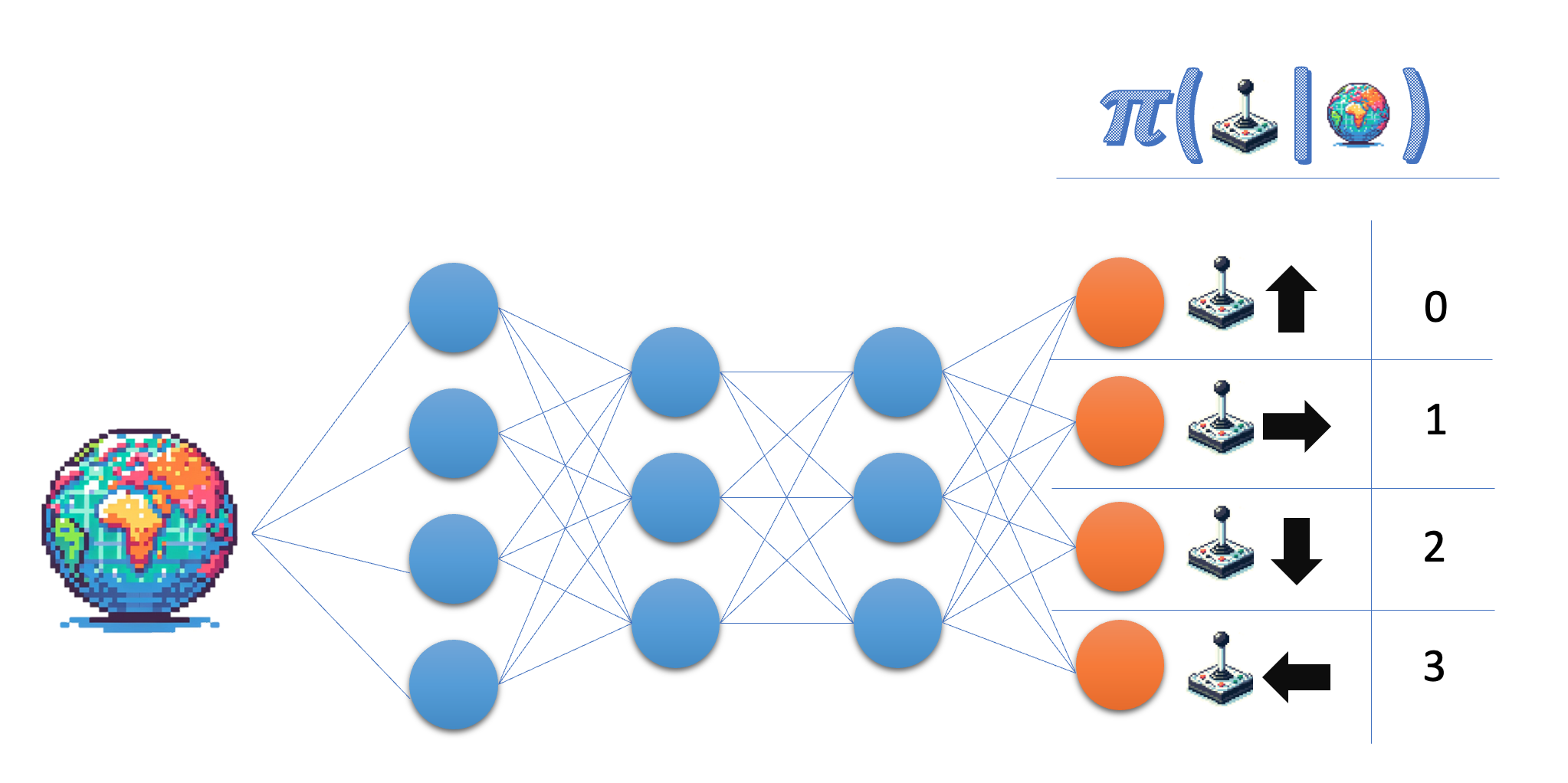
Le réseau de politiques prend l'état comme entrée et produit une probabilité dans l'espace d'action. Dans l'environnement Lunar Lander, vous travaillez avec quatre actions distinctes. Vous souhaitez donc que votre réseau génère une probabilité pour chacune de ces actions.
Cet exercice fait partie du cours
<cours>Apprentissage par renforcement profond en Python</cours>Instructions de l’exercice
- Indiquez la taille de la couche de sortie du réseau de politiques ; pour plus de flexibilité, utilisez le nom de la variable plutôt que le nombre réel.
- Veuillez vous assurer que la couche finale renvoie des probabilités.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)