Matriz de confusión
Con la función confusion_matrix() de scikit-learn puedes generar fácilmente la matriz de confusión de tu clasificador y obtener una visión más detallada de su rendimiento. Acepta dos argumentos: las etiquetas reales de tu conjunto de prueba, y_test, y tus etiquetas predichas.
Las etiquetas predichas de tu clasificador Random Forest del ejercicio anterior están guardadas en y_pred y se calcularon así:
y_pred = clf.predict(X_test)
Nota importante: de forma predeterminada, sklearn calcula la matriz de confusión del siguiente modo:
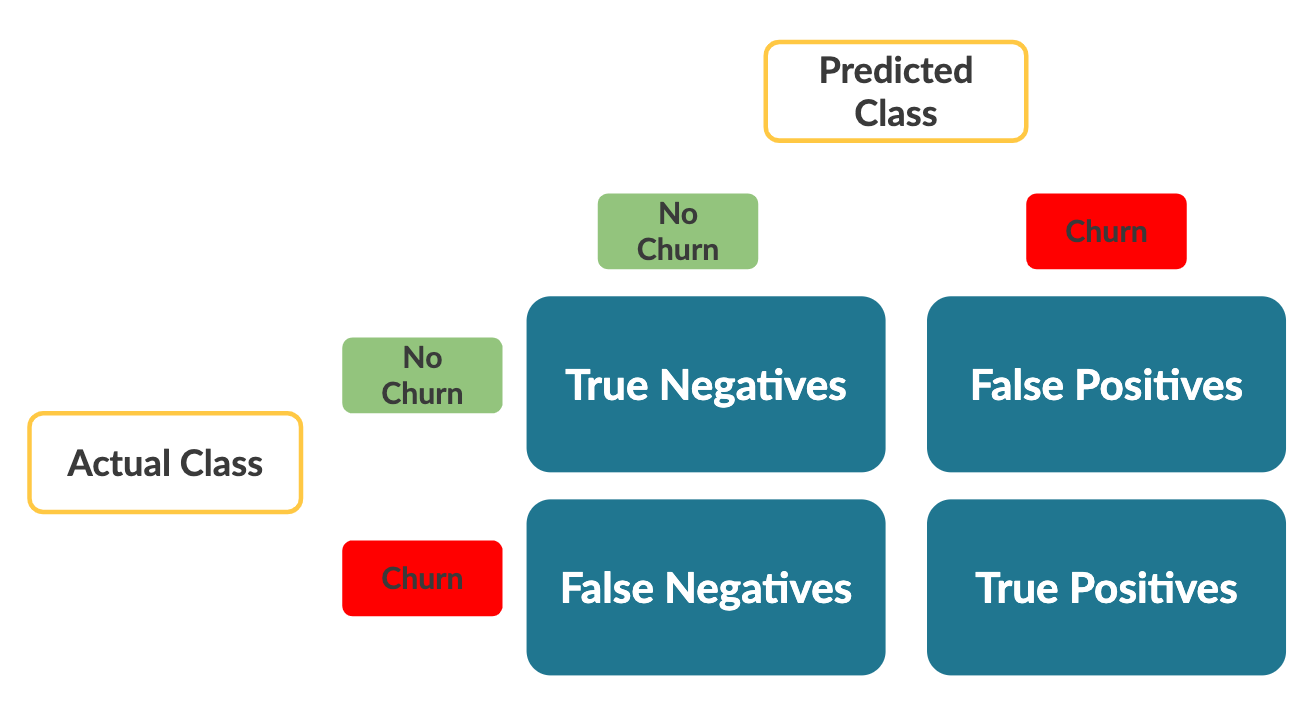
Fíjate en que los ejes están al revés de lo que viste en el vídeo. Las métricas en sí no cambian, pero tenlo en cuenta al interpretar la tabla.
Este ejercicio forma parte del curso
Marketing Analytics: Predicción de churn de clientes en Python
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Import confusion_matrix