Entrenamiento del modelo basado en la incrustación de palabras
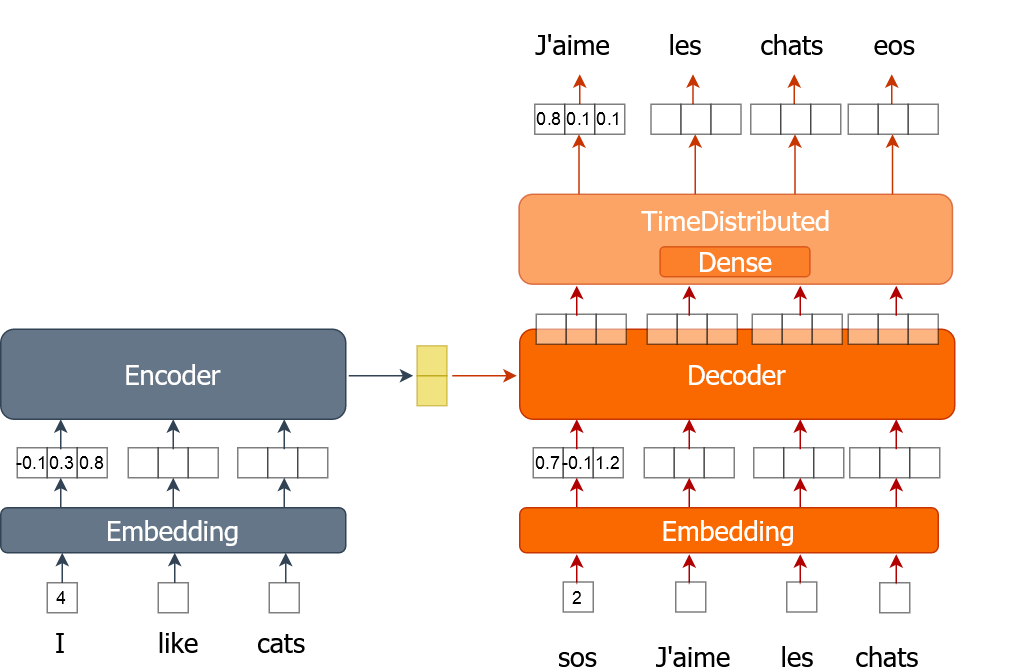
Aquí aprenderás a implementar el proceso de entrenamiento de un modelo de traducción automática que utiliza word embeddings. Una palabra se representa como un único número en lugar de un vector codificado «one-hot», como hiciste en los ejercicios anteriores. Entrenarás el modelo durante múltiples épocas mientras recorres todo el conjunto de datos en lotes.
Para este ejercicio, se te proporcionan datos de entrenamiento (tr_en y tr_fr) en forma de lista de frases. Solo utilizarás una muestra muy pequeña (1000 frases) de los datos reales, ya que, de lo contrario, el entrenamiento podría llevar mucho tiempo. También tienes la función « sents2seqs() » y el modelo « nmt_emb » que implementaste en el ejercicio anterior. Recuerda que utilizamos en_x para referirnos a las entradas del codificador y de_x para referirnos a las entradas del decodificador.
Este ejercicio forma parte del curso
Traducción automática con Keras
Instrucciones del ejercicio
- Obtén un único lote de frases en francés sin codificación onehot utilizando la función «
sents2seqs()». - Obtén todas las palabras excepto la última de
de_xy. - Obtén todas las palabras excepto la primera de
de_xy_oh(palabras francesas con codificación onehot). - Entrena el modelo utilizando un único lote de datos.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))