1.ª parte: Modelo de inversión de texto - Codificador
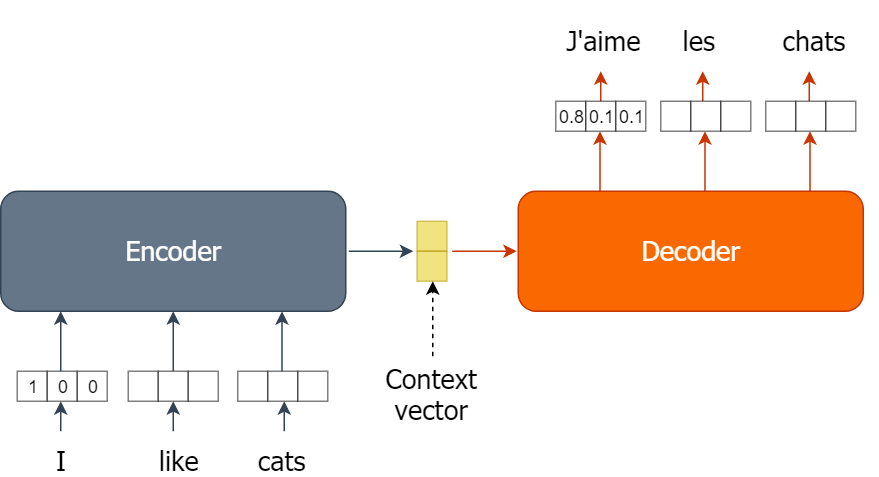
Crear un modelo sencillo de inversión de texto es un método excelente para comprender el funcionamiento de los modelos de codificador-decodificador y cómo se conectan entre sí. Ahora implementarás la parte del codificador de un modelo de inversión de texto.
La implementación del codificador se ha dividido en dos ejercicios. En este ejercicio, definirás la función auxiliar « words2onehot() ». La función « words2onehot() » debe tomar una lista de palabras y un diccionario « word2index » y convertir la lista de palabras en un arreglo de vectores «one-hot». El diccionario « word2index » está disponible en el espacio de trabajo.
Este ejercicio forma parte del curso
Traducción automática con Keras
Instrucciones del ejercicio
- Convierte palabras en ID utilizando el diccionario «
word2index» en la función «words2onehot()». - Convierte los ID de palabras en vectores onehot con una longitud e
3e (utilizando el argumento «num_classes») y devuelve el arreglo resultante. - Llama a la función «
words2onehot()» con las palabras «I», «like» y «cats» y asigna el resultado a «onehot». - Imprime las palabras y sus vectores onehot correspondientes utilizando las funciones
print()yzip(). La función «zip()» te permite iterar varias listas al mismo tiempo.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
import numpy as np
def words2onehot(word_list, word2index):
# Convert words to word IDs
word_ids = [____[w] for w in ____]
# Convert word IDs to onehot vectors and return the onehot array
onehot = ____(____, num_classes=3)
return ____
words = ["I", "like", "cats"]
# Convert words to onehot vectors using words2onehot
onehot = ____(____, ____)
# Print the result as (, ) tuples
print([(w,ohe.tolist()) for ____,____ in zip(words, ____)])