Segmentación de clientes
En este ejercicio, vas a realizar una segmentación de clientes con el conjunto de datos Mall Customer Segmentation usando un modelo de clustering con privacidad diferencial.
En K-means, puedes calcular el número óptimo de clusters con el método del codo.
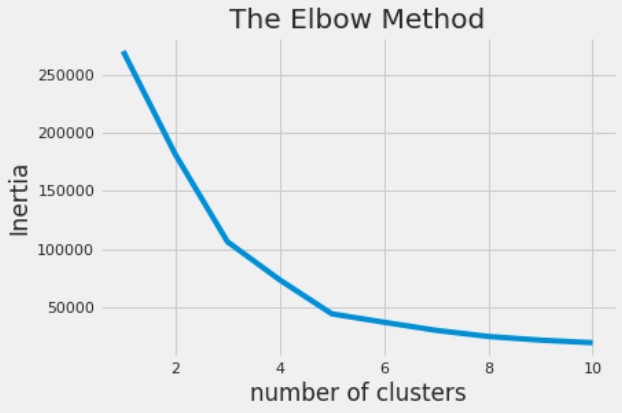
Annual Income y Spending Score, que se han cargado como X, y representarás los clusters resultantes.
El conjunto de datos completo se ha cargado como mall_df. Para tu comodidad, se te proporciona una función personalizada show_clusters() para trazar los clusters. Usa ?show_clusters para saber más.
Este ejercicio forma parte del curso
Privacidad de datos y anonimización en Python
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Build the differentially private K-means model
model = ____