Patrones de clustering uniformes
Ahora que ya conoces el impacto de las semillas, veamos el sesgo de k-means hacia la formación de clusters uniformes.
Para el siguiente ejercicio usaremos un conjunto de datos con forma de ratón. Un conjunto de datos con forma de ratón es un grupo de puntos que recuerda a la cabeza de un ratón: tiene tres clusters de puntos dispuestos en círculos, uno para la cara y dos para las orejas.
Así es como suele verse un conjunto de datos con forma de ratón (Fuente).
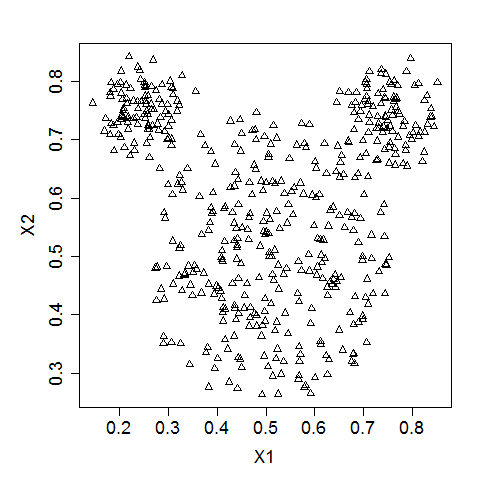
Los datos están almacenados en un DataFrame de pandas, mouse. x_scaled e y_scaled son los nombres de las columnas con las coordenadas X e Y estandarizadas de los puntos.
Este ejercicio forma parte del curso
Análisis de clústeres en Python
Instrucciones del ejercicio
- Importa las funciones
kmeansyvqde SciPy. - Genera los centros de los clusters usando la función
kmeans()con tres clusters. - Crea las etiquetas de cluster con
vq()usando los centros generados arriba.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Import the kmeans and vq functions
____
# Generate cluster centers
cluster_centers, distortion = ____
# Assign cluster labels
mouse['cluster_labels'], distortion_list = ____
# Plot clusters
sns.scatterplot(x='x_scaled', y='y_scaled',
hue='cluster_labels', data = mouse)
plt.show()