Das Datenbankschema
Mittlerweile weißt du, dass SQL-Datenbanken immer ein Datenbankschema haben. Im Video über Datenbanken hast du die folgende Übersicht gesehen:
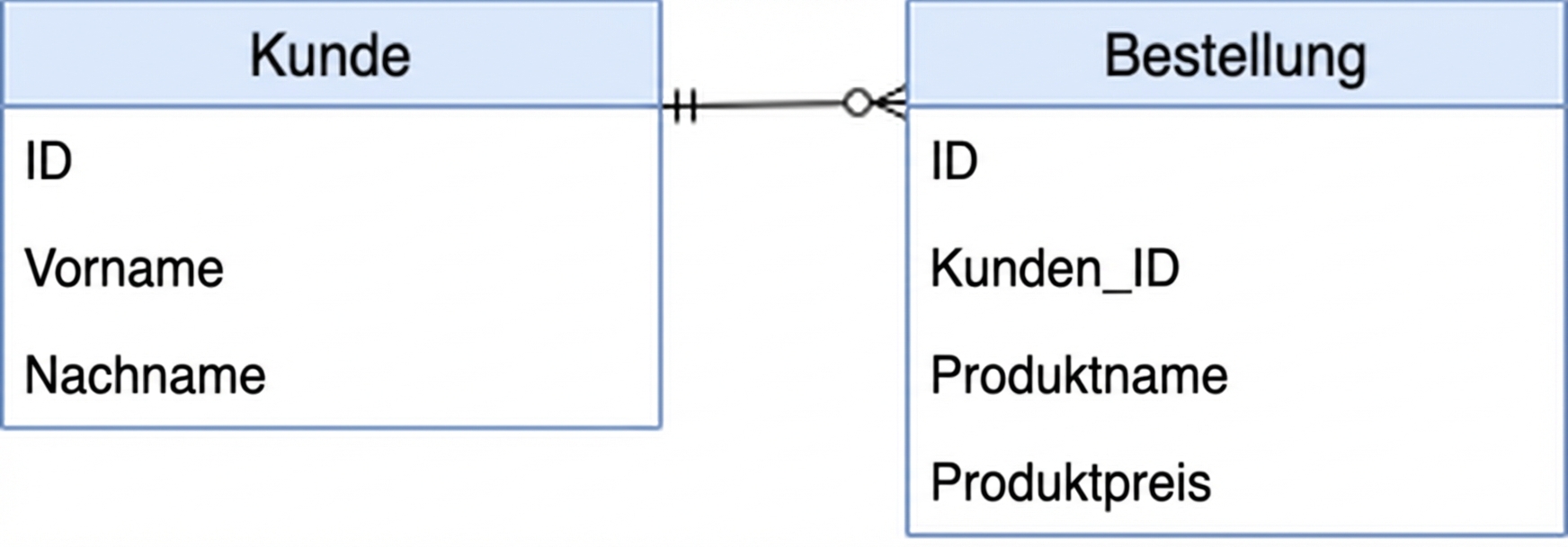
In deiner lokalen Umgebung ist eine PostgreSQL-Datenbank eingerichtet, die dieses Datenbankschema enthält. Es wurde mit ein paar Beispieldaten gefüllt. Du kannst pandas nutzen, um die Datenbank mit der Funktion read_sql() abzufragen. Du musst ihr eine Datenbank-Engine übergeben, die für dich definiert wurde und db_engine heißt.
Das Paket pandas, das als pd importiert wird, speichert das Abfrageergebnis in einem DataFrame-Objekt, sodass du nach dem Abrufen der Ergebnisse aus der Datenbank alle DataFrame-Funktionen darauf anwenden kannst.
Diese Übung ist Teil des Kurses
<Kurs>Einführung in das Data Engineering</Kurs>Übungsanweisungen
- Vervollständige die Anweisung
SELECT, sodass sie die Spaltenfirst_nameundlast_nameaus der Tabelle"Customer"auswählt. Stell sicher, dass du zuerst nach Nachnamen und dann nach Vornamen ordnest. - Verwende die Methode
.head(), um die ersten3Zeilen vondataanzuzeigen. - Nutze
.info(), um ein paar allgemeine Informationen überdataanzuzeigen.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Complete the SELECT statement
data = pd.read_sql("""
SELECT first_name, ____ FROM "____"
ORDER BY ____, ____
""", db_engine)
# Show the first 3 rows of the DataFrame
print(data.head(____))
# Show the info of the DataFrame
print(data.____())