Bringe etwas Spark in deine Daten
In der letzten Aufgabe hast du gesehen, wie man Daten von Spark nach pandas verschiebt. Vielleicht möchtest du aber auch in die andere Richtung gehen und einen pandas DataFrame in einen Spark-Cluster stellen! Die Klasse SparkSession hat auch dafür eine Methode.
Die Methode .createDataFrame() nimmt einen pandas DataFrame und gibt einen Spark DataFrame zurück.
Die Ausgabe dieser Methode wird lokal gespeichert, nicht im SparkSession-Katalog. Das bedeutet, dass du alle Spark-DataFrame-Methoden darauf anwenden kannst, aber du kannst nicht in anderen Kontexten auf die Daten zugreifen.
Eine SQL-Abfrage (mit der Methode .sql()), die auf deinen DataFrame verweist, führt beispielsweise zu einem Fehler. Um auf die Daten auf diese Weise zuzugreifen, musst du sie als temporäre Tabelle speichern.
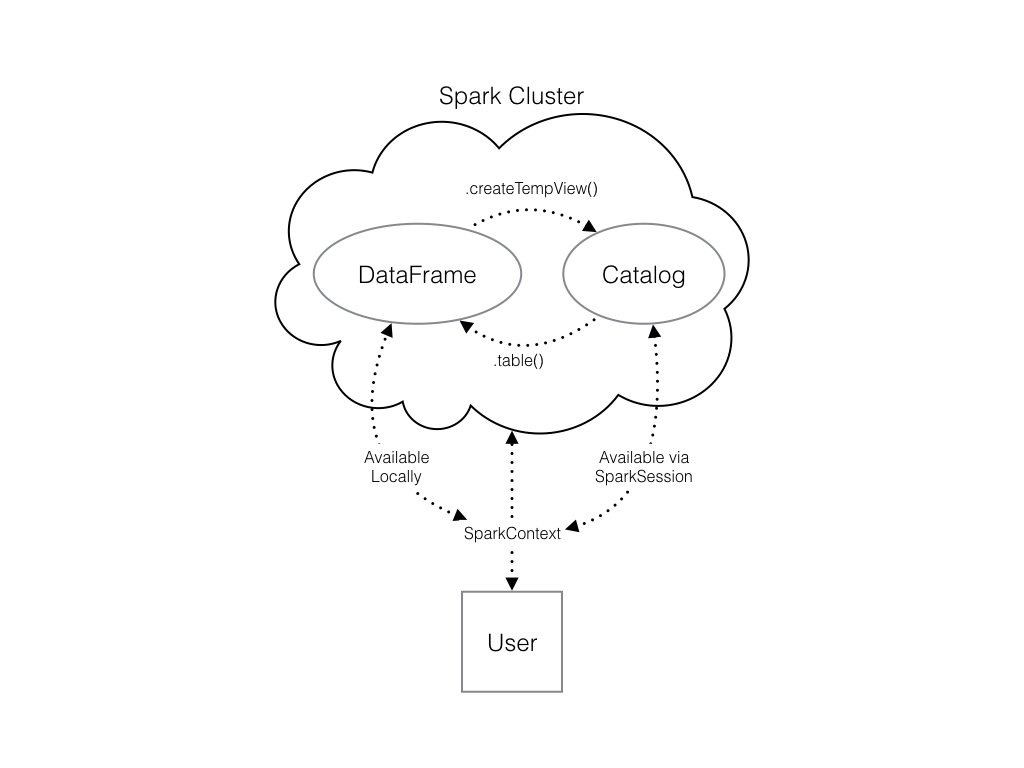
Du kannst dies mit der Methode .createTempView() des Spark DataFrame tun, die als einziges Argument den Namen der temporären Tabelle benötigt, die du registrieren möchtest. Diese Methode registriert den DataFrame als Tabelle im Katalog. Da diese Tabelle jedoch temporär ist, kann nur von der spezifischen SparkSession aus auf sie zugegriffen werden, die zum Erstellen des Spark DataFrame verwendet wurde.
Es gibt außerdem die Methode .createOrReplaceTempView(). Das bedeutet, dass du eine neue temporäre Tabelle erstellen kannst, wenn es vorher keine gab, oder eine bestehende Tabelle aktualisieren kannst, wenn es bereits eine gibt. Mit dieser Methode können Probleme mit doppelten Tabellen vermieden werden.
Schau dir das Diagramm an, um zu sehen, wie deine Spark-Datenstrukturen miteinander interagieren.
In deinem Arbeitsbereich gibt es bereits eine SparkSession mit dem Namen spark, numpy wurde als np importiert und pandas als pd.
Diese Übung ist Teil des Kurses
<Kurs>Einführung in PySpark</Kurs>Übungsanweisungen
- Der Code, um einen
pandasDataFrame mit Zufallszahlen zu erstellen, wurde bereits bereitgestellt und unterpd_tempgespeichert. - Erstelle einen Spark DataFrame namens
spark_temp, indem du die Spark-Methode.createDataFrame()mitpd_tempals Argument aufrufst. - Überprüfe die Liste der Tabellen in deinem Spark-Cluster und stelle sicher, dass der neue DataFrame nicht vorhanden ist. Denke daran, dass du dafür
spark.catalog.listTables()verwenden kannst. - Registriere den DataFrame
spark_temp, den du gerade erstellt hast, mit der Methode.createOrReplaceTempView()als temporäre Tabelle. Die temporäre Tabelle muss den Namen"temp"tragen. Denke daran, dass der Tabellenname festgelegt wird, indem du ihn als einziges Argument in deine Methode aufnimmst! - Sieh dir die Liste der Tabellen noch einmal an.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Create pd_temp
pd_temp = pd.DataFrame(np.random.random(10))
# Create spark_temp from pd_temp
spark_temp = ____
# Examine the tables in the catalog
print(____)
# Add spark_temp to the catalog
spark_temp.____
# Examine the tables in the catalog again
print(____)