Schritte der Datenpipeline
Eine deiner geschäftskritischeren Datenpipelines bei Sierra Publishing basiert auf einem hochfrequenten Datenstrom, der aus einem Kafka-Datenstream kommt. Wir müssen die Daten einlesen und mit ein paar anderen Datensätzen verknüpfen.
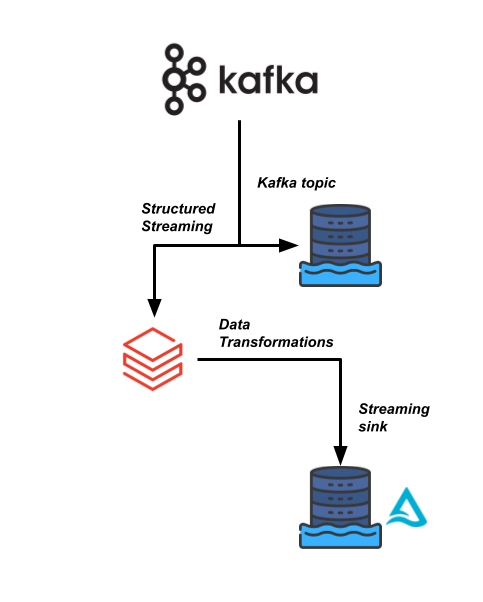
Dein Data-Engineering-Team möchte Databricks nutzen, um diese Datenpipeline effizienter zu machen und es nachgelagerten Nutzer:innen zu ermöglichen, die Daten in Echtzeit für ihre Analysen zu lesen.
Diese Übung ist Teil des Kurses
<Kurs>Databricks-Konzepte</Kurs>Interaktive praktische Übung
Verwandle Theorie mit einer unserer interaktiven Übungen in die Praxis
 Übung starten
Übung starten