Kund:innen segmentieren
In dieser Übung führst du eine Kundensegmentierung mit dem Mall Customer Segmentation Dataset durch – und zwar mit einem differentially privaten Clustering-Modell.
Beim K-Means-Clustering kannst du die optimale Anzahl an Clustern mit der Elbow-Methode bestimmen.
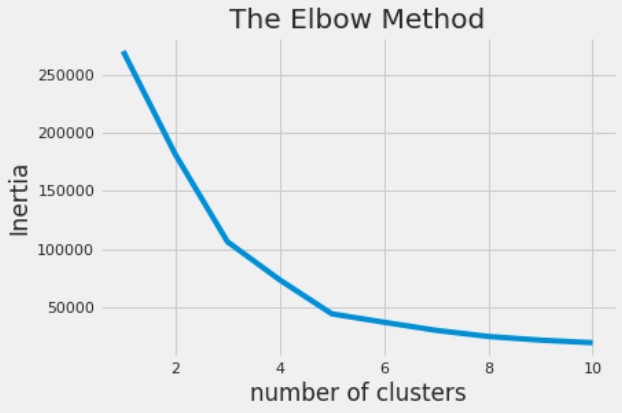
Annual Income und Spending Score, die als X geladen wurden, und visualisierst die resultierenden Cluster.
Der vollständige Datensatz wurde als mall_df geladen. Der Einfachheit halber steht dir die benutzerdefinierte Funktion show_clusters() zum Plotten der Cluster zur Verfügung. Verwende ?show_clusters, um mehr darüber zu erfahren.
Diese Übung ist Teil des Kurses
<Kurs>Datenschutz und Anonymisierung mit Python</Kurs>Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Build the differentially private K-means model
model = ____