Scooter community sentiment
The City Council is curious about how different communities in the City are reacting to the Scooters. The dataset has expanded since Sam's initial analysis, and now contains Vietnamese, Tagalog, Spanish and English reports.
They ask Sam to see if she can figure it out. She decides that the best way to proxy for a community is through language (at least with the data she immediately has access to).
She has already loaded the CSV into the scooter_df variable:
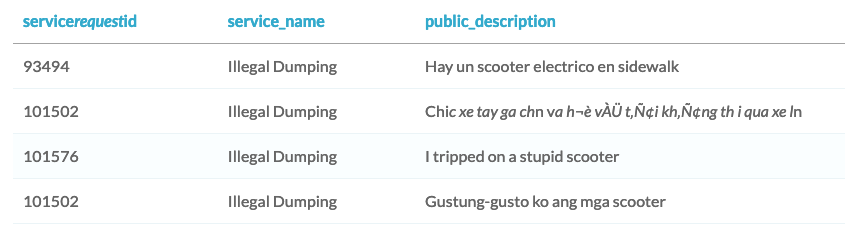
In this exercise, you will help Sam understand sentiment across many different languages. This will help the City understand how different communities are relating to scooters, something that will affect the votes of City Council members.
This exercise is part of the course
Introduction to AWS Boto in Python
Exercise instructions
- For every DataFrame row, detect the dominant language.
- Use the detected language to determine the sentiment of the description.
- Group the DataFrame by the
'sentiment'and'lang'columns in that order.
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
for index, row in scooter_requests.iterrows():
# For every DataFrame row
desc = scooter_requests.loc[index, 'public_description']
if desc != '':
# Detect the dominant language
resp = comprehend.____(____=desc)
lang_code = resp['Languages'][0]['LanguageCode']
scooter_requests.loc[index, 'lang'] = lang_code
# Use the detected language to determine sentiment
scooter_requests.loc[index, 'sentiment'] = comprehend.____(
____=desc,
____=lang_code)['____']
# Perform a count of sentiment by group.
counts = scooter_requests.groupby(['sentiment', 'lang']).count()
counts.head()