Veri hattı adımları
Sierra Publishing'deki iş açısından kritik veri hatlarından biri, Kafka veri akışından gelen yüksek hızlı bir veri akışına dayanıyor. Veriyi okumamız ve birkaç başka veri kümesiyle birleştirmemiz gerekiyor.
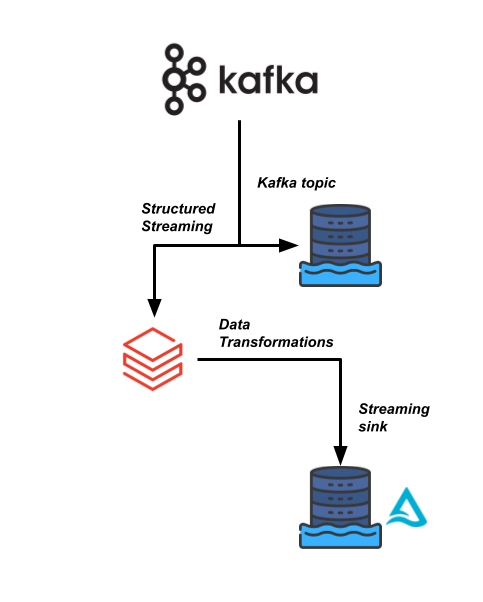
Veri mühendisliği ekibin bu veri hattını daha verimli hale getirmek ve aşağı akıştaki kullanıcıların analizleri için bu veriyi gerçek zamanlı okuyabilmesini sağlamak üzere Databricks kullanmak istiyor.
Bu egzersiz, kursun bir parçasıdır
Databricks Kavramları
Uygulamalı etkileşimli egzersiz
Teoriyi etkileşime dönüştürün, interaktif egzersizlerimizden biriyle
 Egzersize başla
Egzersize başla