Implementando a regra de atualização do Double Q-learning
Double Q-learning é uma extensão do algoritmo Q-learning que ajuda a reduzir a superestimação dos valores de ação mantendo e atualizando duas Q-tables separadas. Ao desacoplar a seleção da ação da avaliação da ação, o Double Q-learning fornece uma estimativa mais precisa dos valores de Q. Este exercício orienta você a implementar a regra de atualização do Double Q-learning. Uma lista Q contendo duas Q-tables já foi gerada.
A biblioteca numpy foi importada como np, e os valores de gamma e alpha foram pré-carregados. As fórmulas de atualização estão abaixo:
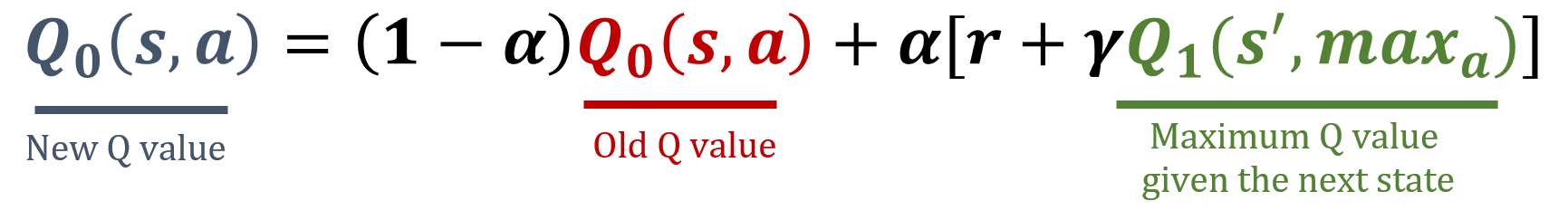
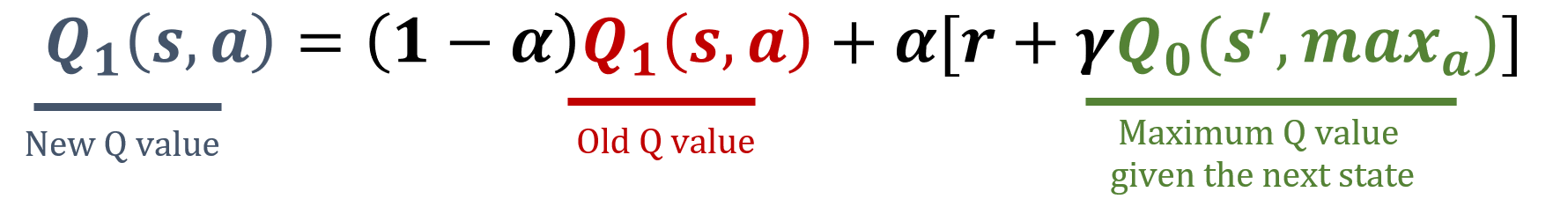
Este exercicio faz parte do curso
Reinforcement Learning com Gymnasium em Python
Instruções do exercicio
- Decida aleatoriamente qual Q-table dentro de
Qserá atualizada para a estimativa do valor da ação, calculando seu índicei. - Execute as etapas necessárias para atualizar
Q[i].
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____