Regra de atualização do Expected SARSA
Neste exercício, você vai implementar a regra de atualização do Expected SARSA, um algoritmo de aprendizado por diferença temporal em Model-Free RL. O Expected SARSA estima o valor esperado da política atual ao fazer a média sobre todas as ações possíveis, oferecendo um alvo de atualização mais estável em comparação ao SARSA. As fórmulas usadas no Expected SARSA estão abaixo.
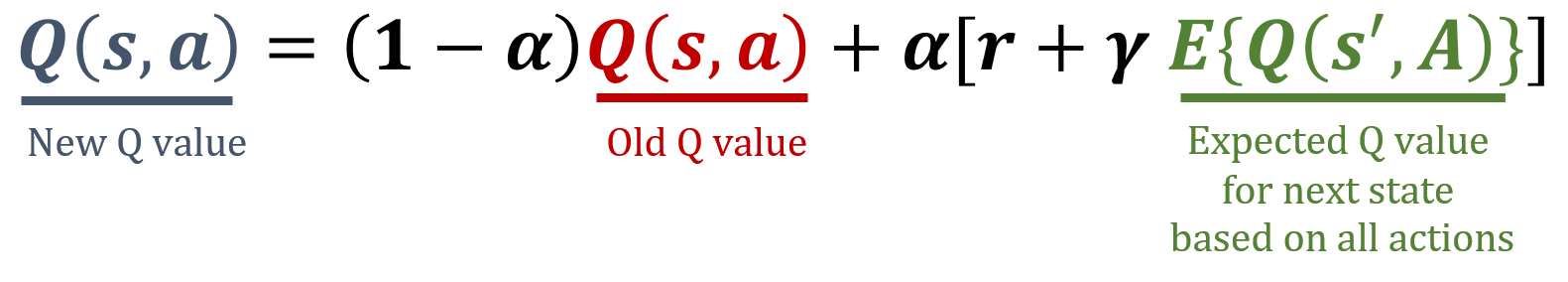
A biblioteca numpy já foi importada como np.
Este exercicio faz parte do curso
Reinforcement Learning com Gymnasium em Python
Instruções do exercicio
- Calcule o Q-valor esperado para o
next_state. - Atualize o Q-valor do
stateeactionatuais usando a fórmula do Expected SARSA. - Atualize a Q-table
Qsupondo que um agente execute a ação1no estado2e vá para o estado3, recebendo uma recompensa de5.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)