Inspecionando o cache na Spark UI
Um dataframe partitioned_df está disponível. Ele é usado para registrar uma tabela temporária chamada text. Em seguida, text é colocado em cache usando spark.catalog.cacheTable('text'). Se você estivesse executando o Spark localmente, a Spark UI estaria disponível em http://localhost:4040/storage/. Para este exercício, analise a imagem a seguir. Ela mostra o que a Spark UI exibiria assim que o cache de text fosse carregado:
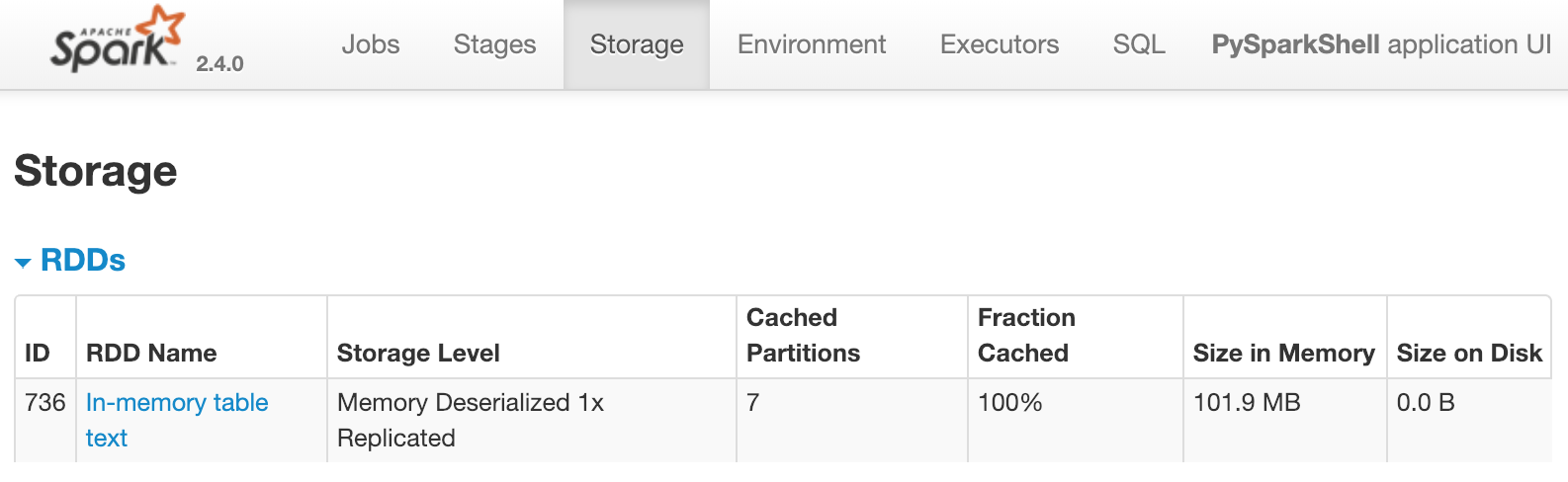
Isso indica que uma tabela chamada text, com sete partições, está em cache na memória. Qual das alternativas a seguir faria com que isso aparecesse imediatamente na Spark UI?
Executar uma transformação no dataframe subjacente, por exemplo:
df = partitioned_df.distinct().Contar o dataframe subjacente, por exemplo:
partitioned_df.count()Consultar a tabela usando, por exemplo:
spark.sql("select count(*) from text")Consultar e mostrar o resultado, por exemplo:
spark.sql("select count(*) from text").show()
Este exercicio faz parte do curso
Introdução ao Spark SQL em Python
exercicio interativo prático
Transforme teoria em prática com um dos nossos exercicio interativos
 Iniciar exercicio
Iniciar exercicio