Lidando com ruído nos rótulos
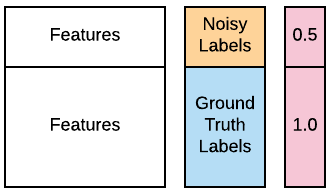
Uma das suas analistas de segurança informa que muitos dos rótulos dos primeiros 100 computadores de origem nos seus dados de treino podem estar errados por causa de um erro no banco de dados. Ela espera que você ainda possa usar os dados, porque a maioria dos rótulos ainda está correta, mas pede que você trate esses 100 rótulos como "ruidosos". Felizmente, você sabe como fazer isso usando aprendizado com pesos. Os dados contaminados estão disponíveis no seu workspace como X_train, X_test, y_train_noisy, y_test. Você quer ver se consegue melhorar o desempenho de um classificador GaussianNB() usando aprendizado com pesos. Você pode usar o parâmetro opcional sample_weight, que é suportado pelos métodos .fit() da maioria dos classificadores populares. A função accuracy_score() já está carregada. Você pode consultar a imagem abaixo para orientação.
Este exercicio faz parte do curso
Projetando Workflows de Machine Learning em Python
Instruções do exercicio
- Ajuste uma instância de
GaussianNB()aos dados de treino com rótulos contaminados. - Informe sua acurácia nos dados de teste usando
accuracy_score(). - Crie pesos que atribuam o dobro de peso aos rótulos de ground truth em relação aos rótulos ruidosos. Lembre-se de que os pesos dizem respeito aos dados de treino.
- Reajuste o classificador usando os pesos acima e informe sua acurácia.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))