Segmentação de clientes
Neste exercício, você fará uma segmentação de clientes (Customer Segmentation) a partir do Mall Customer Segmentation Dataset usando um modelo de clustering com privacidade diferencial.
No K-means, você pode calcular o número ideal de clusters com o método do cotovelo (elbow method).
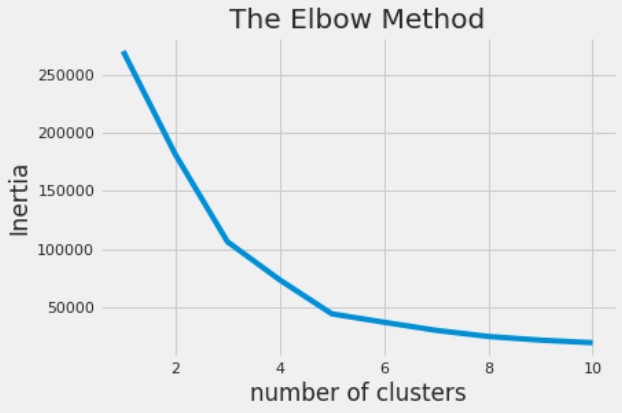
Annual Income e Spending Score, que já foram carregados como X, e plotar os clusters resultantes.
O conjunto de dados completo foi carregado como mall_df. Para facilitar, uma função personalizada show_clusters() para plotar os clusters está disponível. Use ?show_clusters para saber mais.
Este exercicio faz parte do curso
Privacidade de Dados e Anonimização em Python
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Build the differentially private K-means model
model = ____