Cijfers leren herkennen
Je gaat een model bouwen op de digits dataset, een voorbeeldgegevensset die standaard met scikit-learn wordt meegeleverd. De digits dataset bestaat uit 8x8-pixel handgeschreven cijfers van 0 tot en met 9:
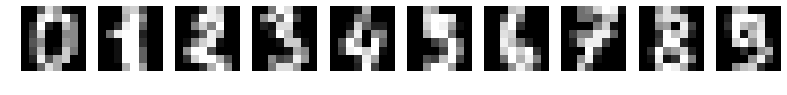
De gegevensset is al opgesplitst in X_train, y_train, X_test en y_test, waarbij 30% als testgegevens is gebruikt. De labels zijn al one-hot encoded vectoren, dus je hoeft de Keras-functie to_categorical() niet te gebruiken.
Laten we dit nieuwe model bouwen!
Deze oefening maakt deel uit van de cursus
Introductie tot Deep Learning met Keras
Oefeninstructies
- Voeg een
Dense-laag toe met 16 neuronen,relu-activatie en eeninput_shapedie het totaal aantal pixels van de 8x8-cijferafbeelding gebruikt. - Voeg een
Dense-laag toe met 10 outputs ensoftmax-activatie. - Compileer je model met
adam,categorical_crossentropyen deaccuracy-metriek. - Controleer of je model werkt door te voorspellen op
X_train.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Instantiate a Sequential model
model = Sequential()
# Input and hidden layer with input_shape, 16 neurons, and relu
model.add(Dense(____, input_shape = (____,), activation = ____))
# Output layer with 10 neurons (one per digit) and softmax
model.____(____)
# Compile your model
model.____(optimizer = ____, loss = ____, metrics = [____])
# Test if your model is well assembled by predicting before training
print(model.predict(____))