Portfolio-prestatie met gradient boosting
Je hebt nu gekeken naar het voorspellen van de probability of default met zowel LogisticRegression() als XGBClassifier(). Je hebt scores bekeken en voorbeelden van voorspellingen gezien, maar wat is het totale effect op de portfolio-prestatie? Gebruik expected loss als scenario om het belang van het testen van verschillende modellen te laten zien.
Er is een data frame portfolio gemaakt waarin de probabilities of default voor beide modellen zijn gecombineerd, de loss given default (ga voorlopig uit van 20%) en de loan_amnt, die we aannemen als de exposure at default.
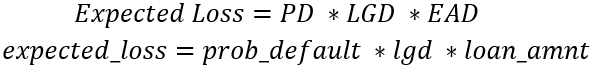
De data frame cr_loan_prep en de trainingsets X_train en y_train zijn in de workspace geladen.
Deze oefening maakt deel uit van de cursus
Kredietrisicomodellering in Python
Oefeninstructies
- Print de eerste vijf rijen van
portfolio. - Maak de kolom
expected_lossvoor hetgbt- enlr-model met de namengbt_expected_lossenlr_expected_loss. - Print de som van
lr_expected_lossvoor de volledigeportfolio. - Print de som van
gbt_expected_lossvoor de volledigeportfolio.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Print the first five rows of the portfolio data frame
print(____.____())
# Create expected loss columns for each model using the formula
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
# Print the sum of the expected loss for lr
print('LR expected loss: ', np.____(____[____]))
# Print the sum of the expected loss for gbt
print('GBT expected loss: ', np.____(____[____]))