Implementare la regola di aggiornamento del Double Q-learning
Il Double Q-learning è un’estensione dell’algoritmo Q-learning che aiuta a ridurre la sovrastima dei valori d’azione mantenendo e aggiornando due Q-table distinte. Separando la selezione dell’azione dalla sua valutazione, il Double Q-learning fornisce una stima più accurata dei Q-value. In questo esercizio implementerai la regola di aggiornamento del Double Q-learning. È stata generata una lista Q che contiene due Q-table.
La libreria numpy è stata importata come np, e i valori di gamma e alpha sono già caricati. Le formule di aggiornamento sono riportate di seguito:
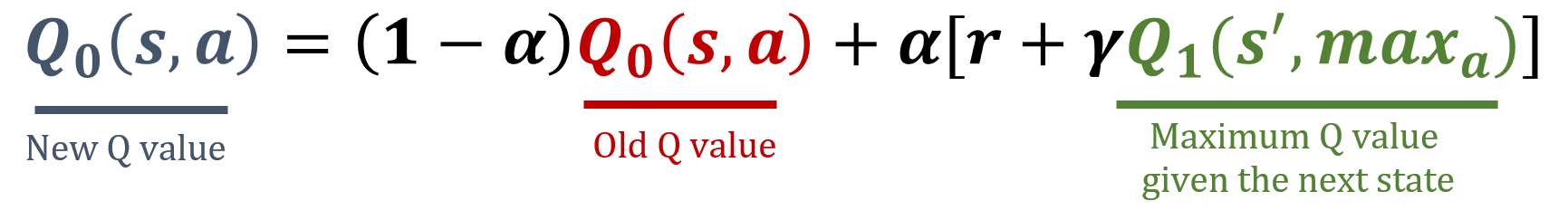
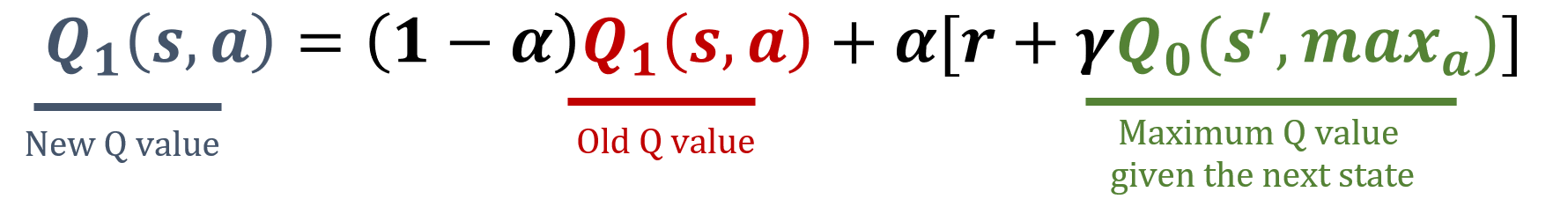
Questo esercizio fa parte del corso
Reinforcement Learning con Gymnasium in Python
Istruzioni dell'esercizio
- Decidi in modo casuale quale Q-table all’interno di
Qaggiornare per la stima del valore d’azione, calcolandone l’indicei. - Esegui i passaggi necessari per aggiornare
Q[i].
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____