Regola di aggiornamento di Expected SARSA
In questo esercizio implementerai la regola di aggiornamento di Expected SARSA, un algoritmo di tipo temporal difference e model-free in Reinforcement Learning. Expected SARSA stima il valore atteso della politica corrente mediando su tutte le possibili azioni, offrendo un obiettivo di aggiornamento più stabile rispetto a SARSA. Le formule usate in Expected SARSA sono riportate sotto.
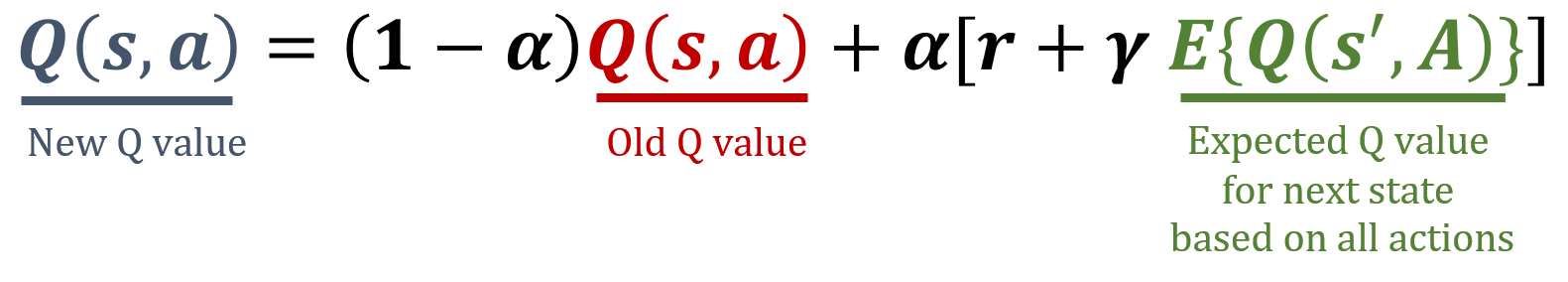
La libreria numpy è stata importata come np.
Questo esercizio fa parte del corso
Reinforcement Learning con Gymnasium in Python
Istruzioni dell'esercizio
- Calcola il Q-value atteso per il
next_state. - Aggiorna il Q-value per lo
statee l'actioncorrenti usando la formula di Expected SARSA. - Aggiorna la Q-table
Qsupponendo che un agente esegua l'azione1nello stato2e passi allo stato3, ricevendo una ricompensa pari a5.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)