Ispezionare la cache nella Spark UI
È disponibile un dataframe partitioned_df. Viene usato per registrare una tabella temporanea chiamata text. Poi text viene messa in cache usando spark.catalog.cacheTable('text'). Se eseguissi Spark in locale, la Spark UI sarebbe disponibile su http://localhost:4040/storage/. Per questo esercizio, osserva l'immagine seguente. Mostra cosa visualizzerebbe la Spark UI una volta che la cache di text è stata caricata:
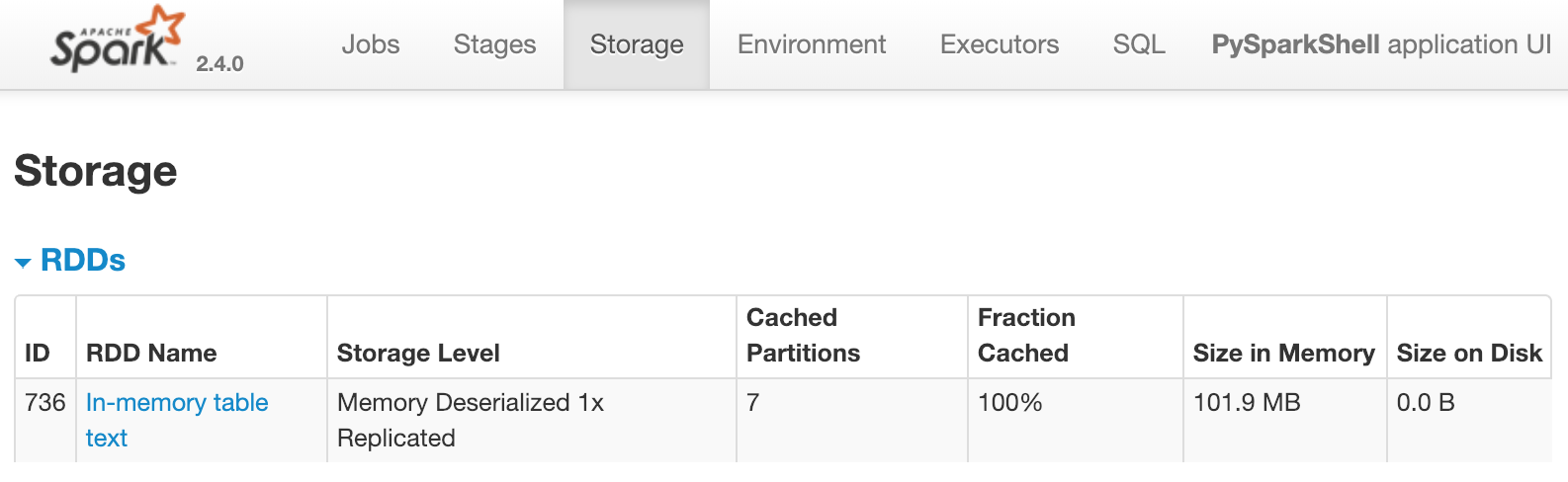
Questo indica che una tabella chiamata text con sette partizioni è in cache in memoria. Quale delle seguenti opzioni farebbe apparire immediatamente quanto sopra nella Spark UI?
Eseguire una trasformazione sul dataframe sottostante, ad esempio
df = partitioned_df.distinct().Contare il dataframe sottostante, ad esempio:
partitioned_df.count()Interrogare la tabella usando, per esempio:
spark.sql("select count(*) from text")Interrogare e mostrare il risultato, per esempio:
spark.sql("select count(*) from text").show()
Questo esercizio fa parte del corso
Introduzione a Spark SQL in Python
esercizio interattivo pratico
Trasforma la teoria in pratica con uno dei nostri esercizi interattivi
 Inizia esercizio
Inizia esercizio