Fasi della pipeline di dati
Una delle pipeline di dati più critiche per il business in Sierra Publishing si basa su uno stream ad alta velocità proveniente da un flusso dati Kafka. Dobbiamo leggere i dati e unirli con alcuni altri insiemi di dati.
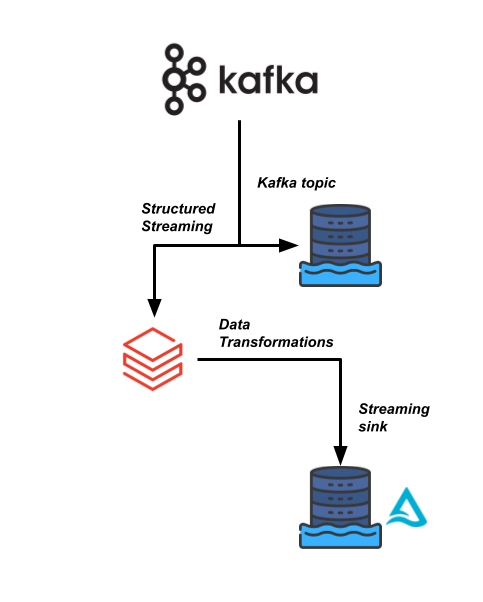
Il tuo team di data engineering vorrebbe usare Databricks per rendere questa pipeline più efficiente e permettere ai consumer a valle di leggere questi dati in tempo reale per le loro analisi.
Questo esercizio fa parte del corso
Concetti di Databricks
esercizio interattivo pratico
Trasforma la teoria in pratica con uno dei nostri esercizi interattivi
 Inizia esercizio
Inizia esercizio