Melatih model berbasis word embedding
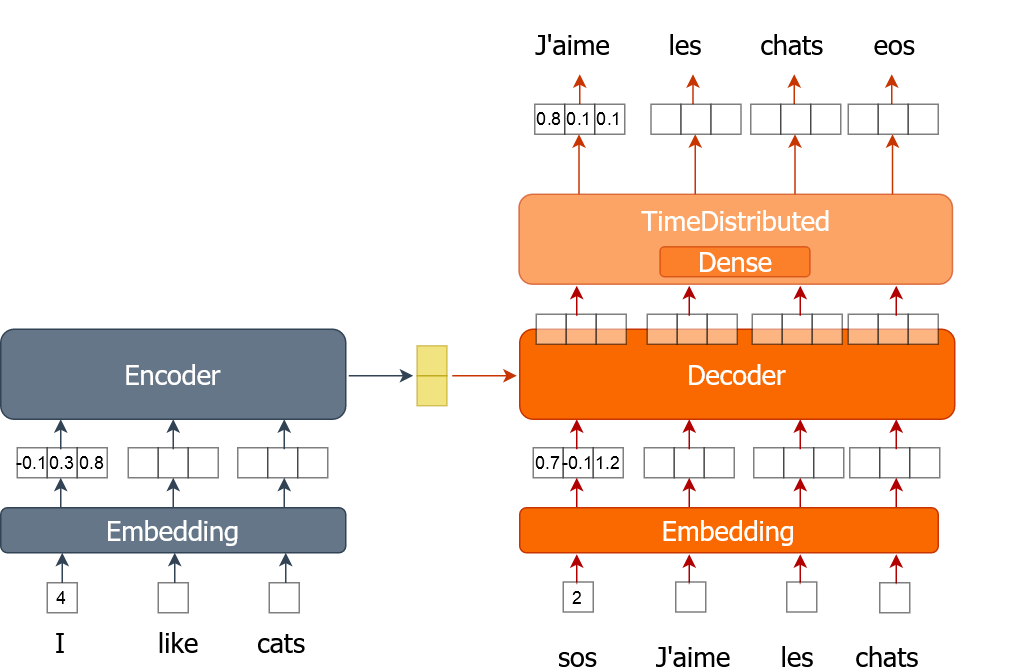
Di sini Anda akan mempelajari cara mengimplementasikan proses pelatihan untuk model penerjemah mesin yang menggunakan word embedding. Sebuah kata direpresentasikan sebagai satu angka alih-alih vektor one-hot encoded seperti yang Anda lakukan pada latihan sebelumnya. Anda akan melatih model selama beberapa epoch sambil menjelajahi seluruh himpunan data dalam batch.
Untuk latihan ini, Anda disediakan data pelatihan (tr_en dan tr_fr) berupa daftar kalimat. Anda hanya akan menggunakan sampel yang sangat kecil (1000 kalimat) dari data sebenarnya karena jika tidak, pelatihan akan memakan waktu sangat lama. Anda juga memiliki fungsi sents2seqs() dan model, nmt_emb, yang Anda implementasikan pada latihan sebelumnya. Ingat bahwa kita menggunakan en_x untuk menyebut masukan encoder dan de_x untuk menyebut masukan decoder.
Latihan ini merupakan bagian dari kursus
Penerjemahan Mesin dengan Keras
Instruksi latihan
- Ambil satu batch kalimat bahasa Prancis tanpa onehot encoding menggunakan fungsi
sents2seqs(). - Ambil semua kata kecuali yang terakhir dari
de_xy. - Ambil semua kata kecuali yang pertama dari
de_xy_oh(kata-kata bahasa Prancis dengan onehot encoding). - Latih model menggunakan satu batch data
Latihan interaktif langsung praktik
Cobalah latihan ini dengan melengkapi kode contoh ini.
for ei in range(3):
for i in range(0, train_size, bsize):
en_x = sents2seqs('source', tr_en[i:i+bsize], onehot=False, reverse=True)
# Get a single batch of French sentences with no onehot encoding
de_xy = ____('target', ____[i:i+bsize], ____=____)
# Get all words except the last word in that batch
de_x = de_xy[:,____]
de_xy_oh = sents2seqs('target', tr_fr[i:i+bsize], onehot=True)
# Get all words except the first from de_xy_oh
de_y = de_xy_oh[____,____,____]
# Training the model on a single batch of data
nmt_emb.train_on_batch([____,____], ____)
res = nmt_emb.evaluate([en_x, de_x], de_y, batch_size=bsize, verbose=0)
print("{} => Loss:{}, Train Acc: {}".format(ei+1,res[0], res[1]*100.0))