Langkah-langkah pipeline data
Salah satu pipeline data yang sangat krusial bagi bisnis di Sierra Publishing bergantung pada aliran data berkecepatan tinggi yang berasal dari aliran data Kafka. Kita perlu membaca data tersebut dan menggabungkannya dengan beberapa himpunan data lain.
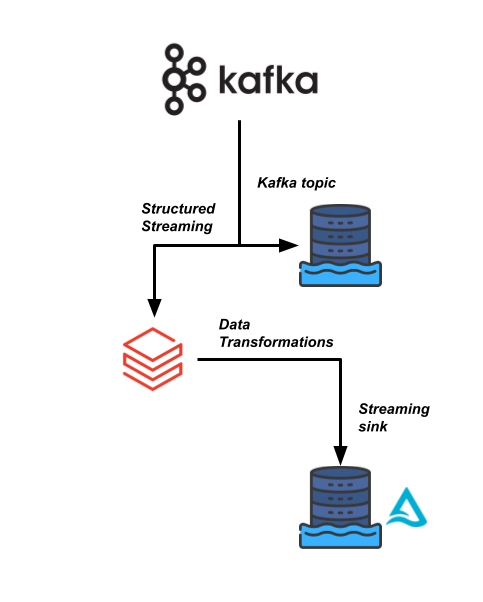
Tim rekayasa data Anda ingin menggunakan Databricks untuk membuat pipeline data ini lebih efisien dan memungkinkan konsumen hilir membaca data ini secara real time untuk analitik mereka.
Latihan ini merupakan bagian dari kursus
Konsep Databricks
Latihan interaktif langsung
Ubah teori menjadi aksi dengan salah satu latihan interaktif kami
 Mulai latihan
Mulai latihan