Gérer le bruit dans les labels
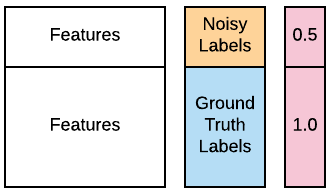
L’une de vos analystes cybersécurité vous informe que nombre des labels des 100 premiers ordinateurs sources de vos données d’entraînement peuvent être erronés à cause d’un problème de base de données. Elle espère que vous pourrez quand même utiliser ces données, car la plupart des labels restent corrects, mais vous demande de considérer ces 100 labels comme « bruités ». Heureusement, vous savez gérer cela grâce à l’apprentissage pondéré. Les données contaminées sont disponibles dans votre espace de travail sous X_train, X_test, y_train_noisy, y_test. Vous souhaitez vérifier si vous pouvez améliorer les performances d’un classifieur GaussianNB() en utilisant l’apprentissage pondéré. Vous pouvez utiliser le paramètre optionnel sample_weight, pris en charge par les méthodes .fit() de la plupart des classifieurs populaires. La fonction accuracy_score() est préchargée. Vous pouvez consulter l’image ci-dessous pour vous guider.
Cet exercice fait partie du cours
<cours>Concevoir des workflows de Machine Learning en Python</cours>Instructions de l’exercice
- Ajustez une instance de
GaussianNB()sur les données d’entraînement avec les labels contaminés. - Indiquez sa précision sur les données de test à l’aide de
accuracy_score(). - Créez des poids qui attribuent deux fois plus d’importance aux labels de vérité terrain qu’aux labels bruités. N’oubliez pas que les poids concernent les données d’entraînement.
- Réentraîner le classifieur en utilisant ces poids et rapporter sa précision.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))