Letras del código genético
Los componentes básicos del ARN son cuatro moléculas representadas cada una por una sola letra: adenina (A), citosina (C), guanina (G) y uracilo (U). La información que lleva una hebra de ARN puede representarse como una larga secuencia de estas cuatro letras. Para leer este código, hay que dividir la cadena en secuencias de tres letras (p. ej., GCU, ACG, …). Estas secuencias de tres letras se conocen como codones. El concepto se ilustra en la imagen siguiente.
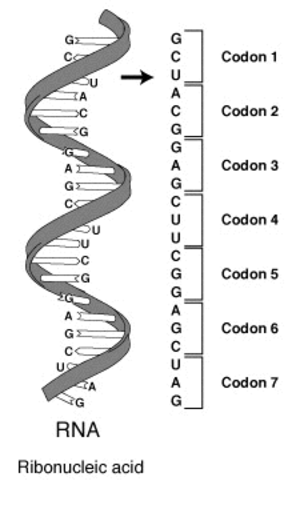
Tu objetivo en este ejercicio es crear un data frame con todas las secuencias posibles de tres letras (codones) a partir de un vector con las cuatro letras que representan los componentes del ARN.
Este ejercicio forma parte del curso
Reestructurar datos con tidyr
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
letters <- c("A", "C", "G", "U")
# Create a tibble with all possible 3 way combinations
codon_df <- ___
codon_df