Implementar la regla de actualización de Double Q-learning
Double Q-learning es una extensión del algoritmo Q-learning que ayuda a reducir la sobreestimación de los valores de acción manteniendo y actualizando dos Q-tables por separado. Al desacoplar la selección de acciones de la evaluación de acciones, Double Q-learning proporciona una estimación más precisa de los valores Q. En este ejercicio vas a implementar la regla de actualización de Double Q-learning. Ya tienes una lista Q que contiene dos Q-tables.
La librería numpy se ha importado como np, y los valores de gamma y alpha ya están cargados. Las fórmulas de actualización están abajo:
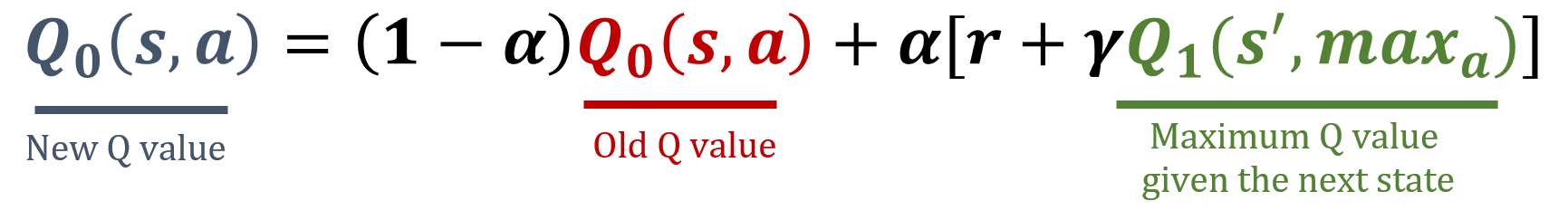
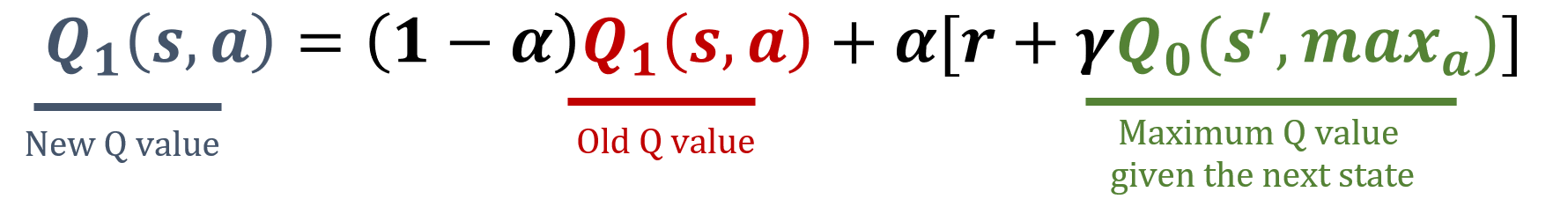
Este ejercicio forma parte del curso
Reinforcement Learning con Gymnasium en Python
Instrucciones del ejercicio
- Decide aleatoriamente qué Q-table dentro de
Qvas a actualizar para la estimación del valor de acción calculando su índicei. - Realiza los pasos necesarios para actualizar
Q[i].
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
Q = [np.random.rand(8,4), np.random.rand(8,4)]
def update_q_tables(state, action, reward, next_state):
# Get the index of the table to update
i = ____
# Update Q[i]
best_next_action = ____
Q[i][state, action] = ____