Regla de actualización de Expected SARSA
En este ejercicio, vas a implementar la regla de actualización de Expected SARSA, un algoritmo de diferencia temporal de RL sin modelo. Expected SARSA estima el valor esperado de la política actual promediando sobre todas las acciones posibles, lo que proporciona un objetivo de actualización más estable que SARSA. Las fórmulas usadas en Expected SARSA están a continuación.
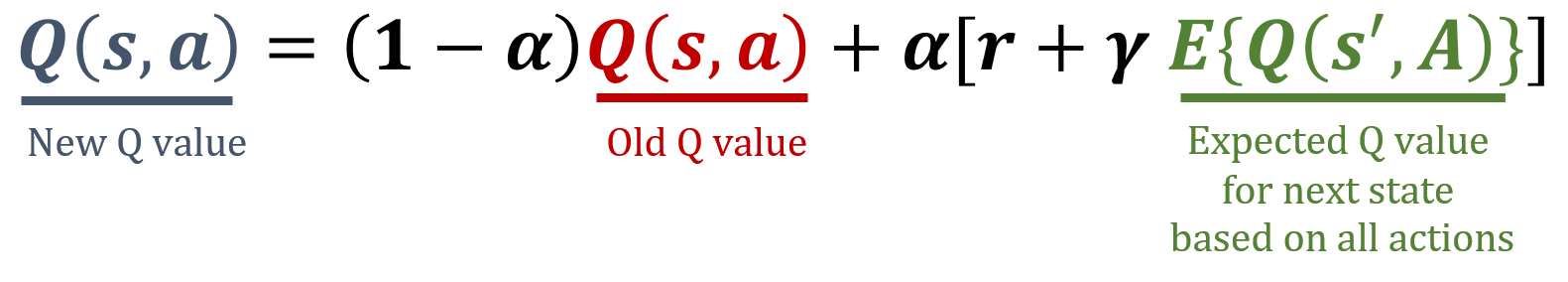
La biblioteca numpy se ha importado como np.
Este ejercicio forma parte del curso
Reinforcement Learning con Gymnasium en Python
Instrucciones del ejercicio
- Calcula el valor Q esperado para
next_state. - Actualiza el valor Q para el
stateyactionactuales usando la fórmula de Expected SARSA. - Actualiza la tabla Q
Qsuponiendo que un agente toma la acción1en el estado2y pasa al estado3, recibiendo una recompensa de5.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
def update_q_table(state, action, next_state, reward):
# Calculate the expected Q-value for the next state
expected_q = ____
# Update the Q-value for the current state and action
Q[state, action] = ____
Q = np.random.rand(5, 2)
print("Old Q:\n", Q)
alpha = 0.1
gamma = 0.99
# Update the Q-table
update_q_table(____, ____, ____, ____)
print("Updated Q:\n", Q)