La arquitectura de la red política
Construye la arquitectura de una Red de Políticas que puedas utilizar más tarde para entrenar a tu agente de gradiente de políticas.
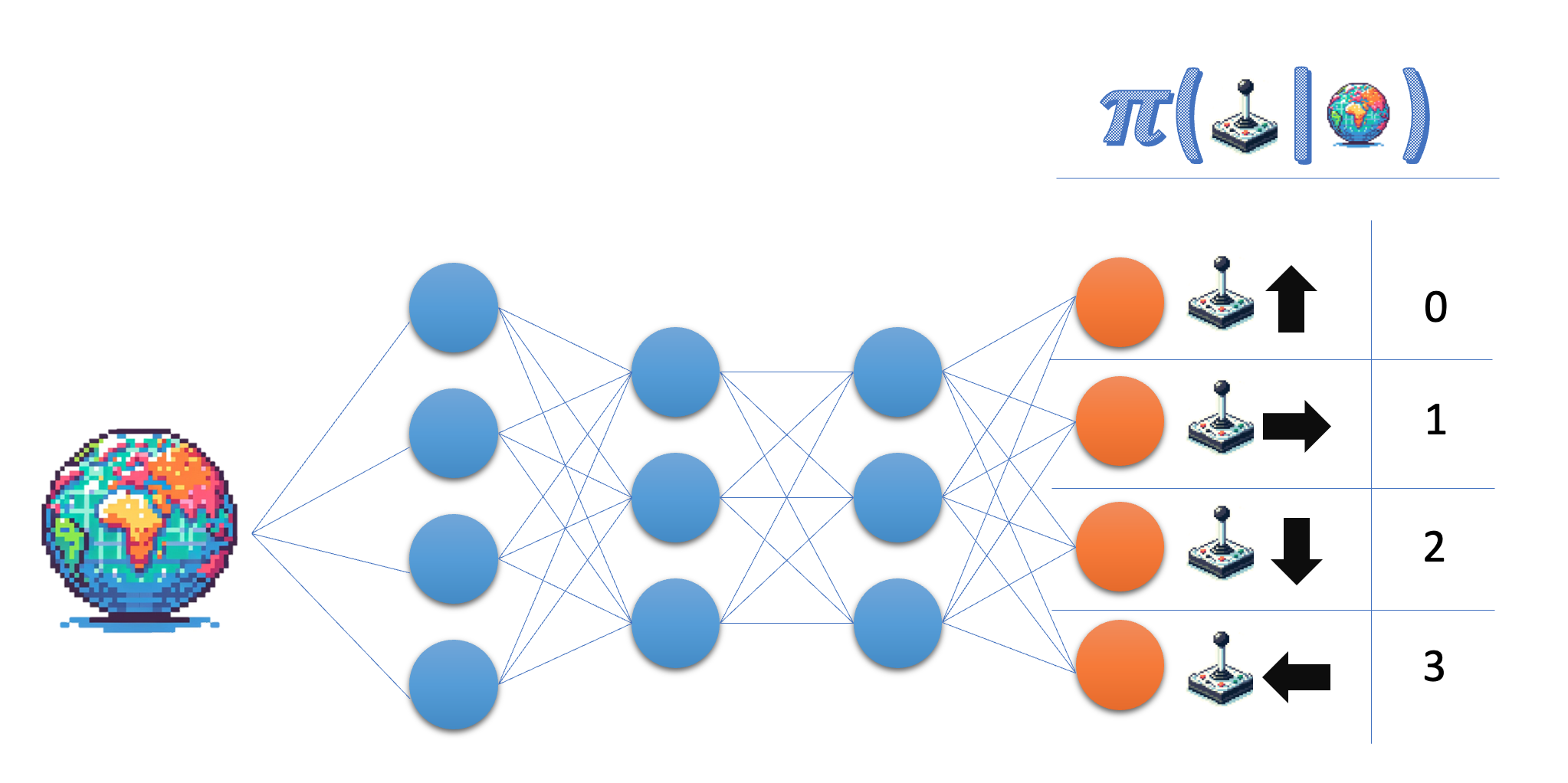
La red política toma el estado como entrada y emite una probabilidad en el espacio de acción. Para el entorno del Lunar Lander, trabajas con cuatro acciones discretas, por lo que quieres que tu red emita una probabilidad para cada una de esas acciones.
Este ejercicio forma parte del curso
Aprendizaje profundo por refuerzo en Python
Instrucciones del ejercicio
- Indica el tamaño de la capa de salida de la red política; para mayor flexibilidad, utiliza el nombre de la variable en lugar del número real.
- Asegúrate de que la capa final devuelve probabilidades.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)