La función objetivo sustitutiva recortada
Implementa la función calculate_loss() para PPO. Esto requiere codificar la innovación clave de PPO: la función de pérdida sustitutiva recortada. Ayuda a restringir la actualización de la política para evitar que se aleje demasiado de la política anterior en cada paso.
La fórmula del objetivo sustitutivo recortado es
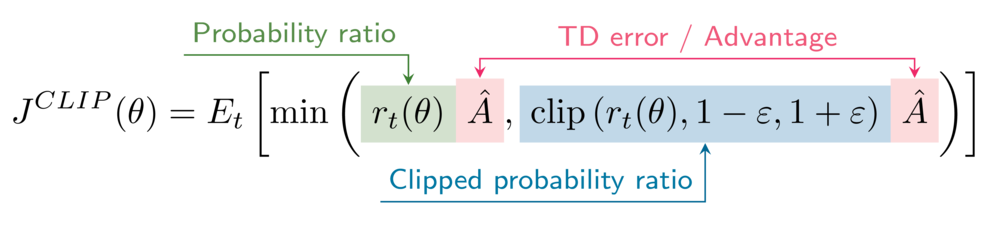
Tu entorno tiene el hiperparámetro de recorte epsilon fijado en 0,2.
Este ejercicio forma parte del curso
Aprendizaje profundo por refuerzo en Python
Instrucciones del ejercicio
- Obtén las relaciones de probabilidad entre
\pi_\thetay\pi_{\theta_{old}}(versiones recortada y no recortada). - Calcula los objetivos sustitutos (versiones recortada y no recortada).
- Calcula el objetivo sustitutivo recortado PPO.
- Calcula la pérdida de actor.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)