Inspecting cache in the Spark UI
A dataframe partitioned_df is available. It is used to register a temporary table called text. text is then cached using spark.catalog.cacheTable('text'). If you were running Spark locally, then the Spark UI would be available at http://localhost:4040/storage/. For the purpose of this exercise, examine the following image. It shows what the Spark UI would display once the cache for text is loaded:
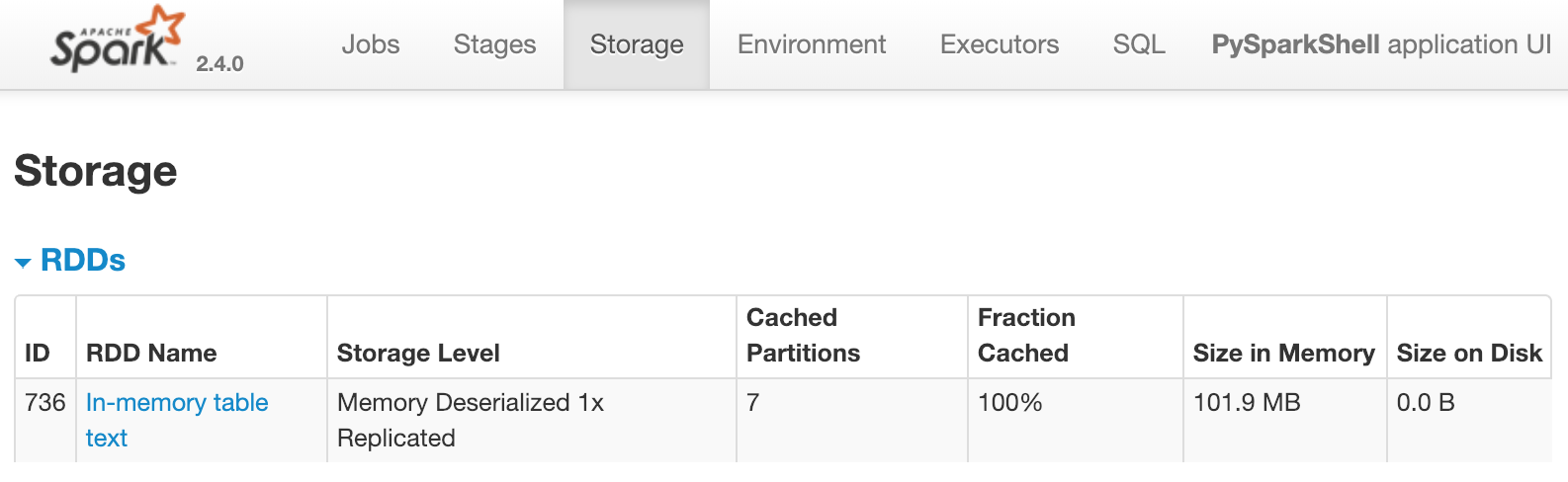
This shows that a table called text having seven partitions is cached in memory. Which of the following would immediately cause the above to appear in Spark UI?
Performing a transform on the underlying dataframe, for example
df = partitioned_df.distinct().Counting the underlying dataframe, for example:
partitioned_df.count()Querying the table using, say:
spark.sql("select count(*) from text")Querying and showing the result, say:
spark.sql("select count(*) from text").show()
This exercise is part of the course
Introduction to Spark SQL in Python
Hands-on interactive exercise
Turn theory into action with one of our interactive exercises
 Start Exercise
Start Exercise