Uniforme clusterpatronen
Nu je bekend bent met het effect van willekeurige starts (seeds), kijken we naar de bias in k-means clustering richting het vormen van uniforme clusters.
We gebruiken voor de volgende oefening een muisachtig gegevenssetje. Een muisachtige gegevensset is een groep punten die lijkt op de kop van een muis: hij heeft drie clusters van punten in cirkels, één voor het gezicht en twee voor de oren van een muis.
Zo ziet een typische muisachtige gegevensset eruit (Bron).
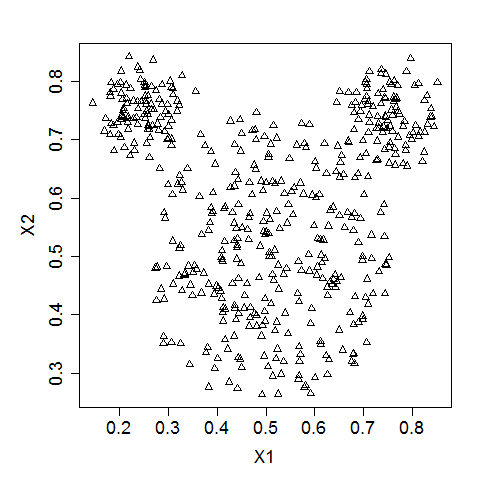
De data staat in een pandas DataFrame, mouse. x_scaled en y_scaled zijn de kolomnamen van de gestandaardiseerde X- en Y-coördinaten van de datapunten.
Deze oefening maakt deel uit van de cursus
Clusteranalyse in Python
Oefeninstructies
- Importeer de functies
kmeansenvqin SciPy. - Genereer clustercentra met de functie
kmeans()met drie clusters. - Maak clusterlabels met
vq()met de hierboven gegenereerde clustercentra.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Import the kmeans and vq functions
____
# Generate cluster centers
cluster_centers, distortion = ____
# Assign cluster labels
mouse['cluster_labels'], distortion_list = ____
# Plot clusters
sns.scatterplot(x='x_scaled', y='y_scaled',
hue='cluster_labels', data = mouse)
plt.show()