Gestire il rumore nelle etichette
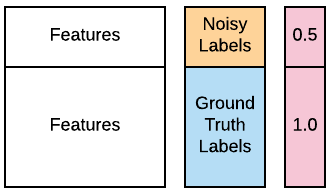
Una tua analista di cybersecurity ti informa che molte delle etichette per i primi 100 computer sorgente nei dati di training potrebbero essere sbagliate a causa di un errore nel database. Sperano che tu possa comunque usare i dati perché la maggior parte delle etichette è ancora corretta, ma ti chiedono di considerare queste 100 etichette come "rumorose". Per fortuna sai come gestirle, usando l'apprendimento pesato. I dati contaminati sono disponibili nel tuo workspace come X_train, X_test, y_train_noisy, y_test. Vuoi verificare se puoi migliorare le prestazioni di un classificatore GaussianNB() usando l'apprendimento pesato. Puoi usare il parametro opzionale sample_weight, supportato dai metodi .fit() della maggior parte dei classificatori più diffusi. La funzione accuracy_score() è già caricata. Puoi consultare l'immagine qui sotto come guida.
Questo esercizio fa parte del corso
Progettare workflow di Machine Learning in Python
Istruzioni dell'esercizio
- Allena un'istanza di
GaussianNB()sui dati di training con etichette contaminate. - Riporta la sua accuratezza sui dati di test usando
accuracy_score(). - Crea pesi che assegnino il doppio del peso alle etichette ground truth rispetto a quelle rumorose. Ricorda che i pesi si riferiscono ai dati di training.
- Allena di nuovo il classificatore usando i pesi sopra e riporta la sua accuratezza.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))