Schemi di clustering uniformi
Ora che hai preso familiarità con l’impatto dei semi (seeds), vediamo il bias del k-means clustering verso la formazione di cluster uniformi.
Per il prossimo esercizio useremo un insieme di dati a forma di topo. Un insieme di dati a forma di topo è un gruppo di punti che ricorda la testa di un topo: presenta tre cluster di punti disposti in cerchi, uno per il muso e due per le orecchie.
Ecco come si presenta tipicamente un insieme di dati a forma di topo (Fonte).
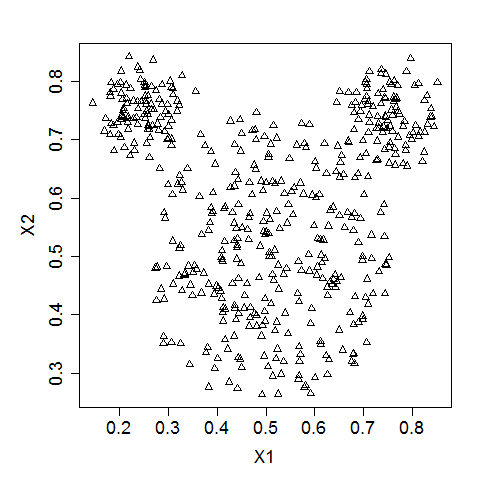
I dati sono memorizzati in un DataFrame di pandas, mouse. x_scaled e y_scaled sono i nomi delle colonne delle coordinate X e Y standardizzate dei punti dati.
Questo esercizio fa parte del corso
Analisi di cluster in Python
Istruzioni dell'esercizio
- Importa le funzioni
kmeansevqda SciPy. - Genera i centri dei cluster usando la funzione
kmeans()con tre cluster. - Crea le etichette di cluster con
vq()utilizzando i centri generati sopra.
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Import the kmeans and vq functions
____
# Generate cluster centers
cluster_centers, distortion = ____
# Assign cluster labels
mouse['cluster_labels'], distortion_list = ____
# Plot clusters
sns.scatterplot(x='x_scaled', y='y_scaled',
hue='cluster_labels', data = mouse)
plt.show()