Segmenter les clients
Dans cet exercice, vous allez réaliser une segmentation client sur le Mall Customer Segmentation Dataset à l’aide d’un modèle de clustering respectant la confidentialité différentielle.
Avec le clustering K-means, vous pouvez calculer le nombre optimal de clusters grâce à la méthode du coude.
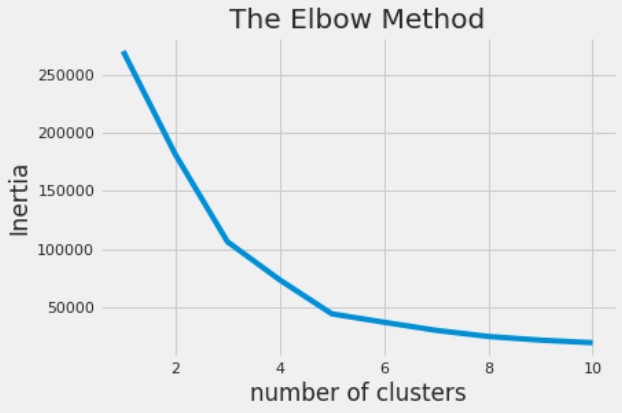
Annual Income et Spending Score, déjà chargés dans X, puis tracer les clusters obtenus.
L’ensemble de données complet est chargé dans mall_df. Pour vous faciliter la tâche, une fonction personnalisée show_clusters() est fournie pour tracer les clusters. Utilisez ?show_clusters pour en savoir plus.
Cet exercice fait partie du cours
<cours>Confidentialité des données et anonymisation en Python</cours>Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Build the differentially private K-means model
model = ____