Inspeccionar la caché en la Spark UI
Hay disponible un dataframe partitioned_df. Se utiliza para registrar una tabla temporal llamada text. Luego, text se almacena en caché con spark.catalog.cacheTable('text'). Si estuvieras ejecutando Spark en local, la Spark UI estaría disponible en http://localhost:4040/storage/. Para este ejercicio, examina la siguiente imagen. Muestra lo que verías en la Spark UI una vez que la caché de text se haya cargado:
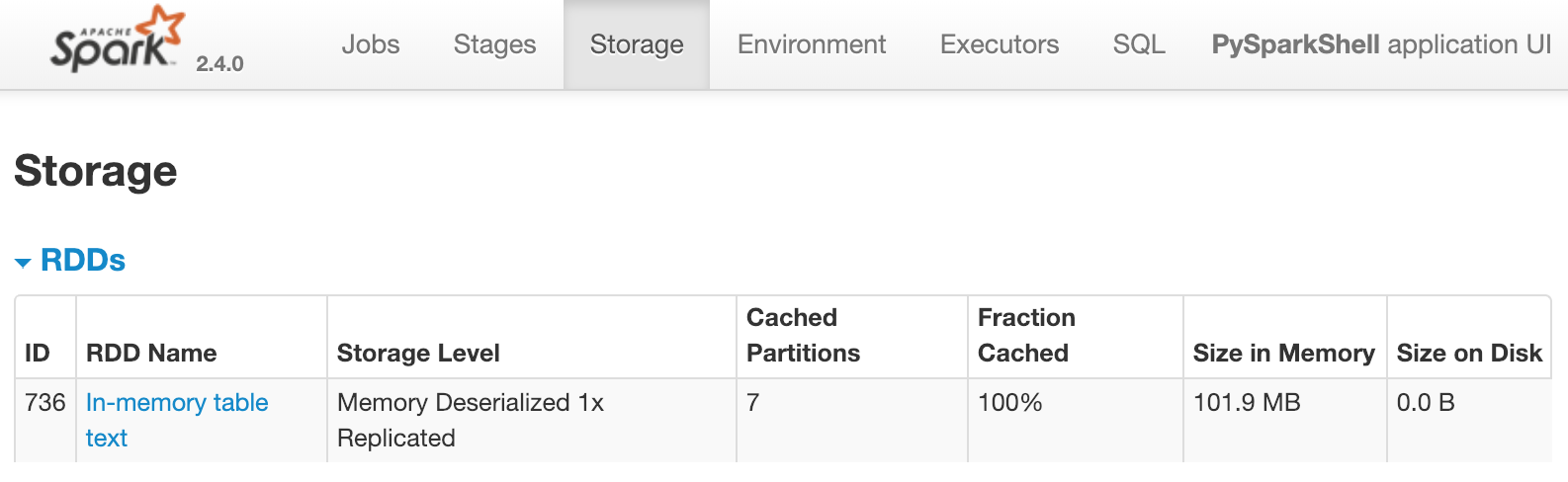
Esto indica que una tabla llamada text con siete particiones está almacenada en memoria. ¿Cuál de las siguientes opciones haría que esto apareciera inmediatamente en la Spark UI?
Realizar una transformación sobre el dataframe subyacente, por ejemplo:
df = partitioned_df.distinct().Contar el dataframe subyacente, por ejemplo:
partitioned_df.count()Consultar la tabla usando, por ejemplo:
spark.sql("select count(*) from text")Consultar y mostrar el resultado, por ejemplo:
spark.sql("select count(*) from text").show()
Este ejercicio forma parte del curso
Introducción a Spark SQL en Python
ejercicio interactivo práctico
Convierte la teoría en práctica con uno de nuestros ejercicios interactivos
 Empezar ejercicio
Empezar ejercicio